
I hadn’t really looked in on the blogs today, but I did take a peek at Twitter, and I got the impression from some of my trusted network of experts that @psychemedia had gone and done something that had gotten them rather excited…
So, I head over and start following the steps in Tony Hirst’s blog, learning that someone can go from this list of statistics in Wikipedia:
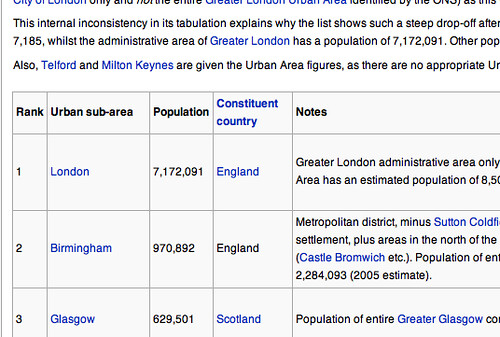
…into this:
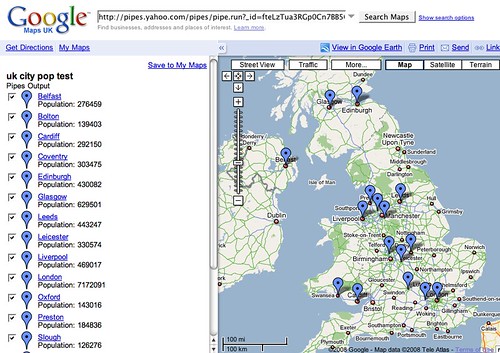
As Tony sums on it up: “we have scraped some data from a wikipedia page into a Google spreadsheet using the =importHTML formula, published a handful of rows from the table as CSV, consumed the CSV in a Yahoo pipe and created a geocoded KML feed from it, and then displayed it in a Yahoo map.” (It seems a lot less intimidating to the data illiterate when you read Tony’s full post.)
Or, to add my own feeble learning here on the sidelines:
* The tools for scraping, manipulating and re-presenting data keep getting easier to use (hell, even I more or less understand the steps Tony lays out here), and you really can do a great deal with free, web-based tools without writing code.
* More and more, I’m starting to think that in addition to being a model for massive scale knowledge building, and an indispensable reference source, that one of Wikipedia’s key contributions to the web will prove to be providing raw material for a range of data mashups such as this one.
* This is what data literacy looks like. To extend the analogy, I’m a first grader right now — I can make out the letters, and sound out the simple words… but the ability to confidently read and write in this form still seems like a form of magic.
Finally, I wasn’t the first to shout it from the rooftops, but let me be the latest: ALL HAIL TONY HIRST!


yep, another amazing Tony Hirst production. I welcome the data literacy discussion. Couldn’t be more perfectly timed as I prep for an intense two days working on our info fluency initiative and am literally just now writing up notes on the relationship between multiple literacies and info fluency. Data literacy… gotta love it.
Of course, superficially this is fine. But if you start to look at the data, it’s rather problematic. I was surprised to see that Manchester was listed as smaller than Bristol, of all places. It was only by going to the Wikipedia page that I understood the way in which the statistics were gathered.
In short, a lot of information has been stripped out in this process. I don’t see much in the way of gain. And in fact, it’s become very misleading.
Where’s the upside?
OK, call me a cynic, but…
Or to put this another way (and in case I didn’t sound grumpy and fuddy-duddy enough the first time), when “data literacy” trumps literacy, we’ve got problems.
@Chris – Info fluency… love it.
@Jon – OK, I will. Cynic!
The upside, as far as I see it, is that Tony took a mostly-unnoticed feature of a free tool that a lot of us were using (Google Docs), realized it could be used to “scrape” data (something that I have always found hard to do reliably)… from any web source with decent HTML. Not just Wikipedia. One thing I see as important about remixing in general is the ability to chase whatever media is remixed back ‘upstream’ – you catch a good example.
I certainly do not mean to suggest data literacy supplants what we think of now as literacy, but that it just might extend the set of skills required to be literate. Just as right now an ability to discern the validity of quality web information is finally gaining legitimacy as “media literacy.”
This is still raw, but it reminds me of the first time I learned how to take a live RSS feed and republish it anywhere. Back then, the ability to do that seemed pointless, and the tools to do so were unreliable… But now?
Hmmm…. maybe you do have a point.
What I see here is the potential for individuals to manipulate bodies of data the way that we can now cut-and-paste text in word processors. Let’s see how it plays out… I know I can count on you to keep up a critical stance Jon, and honestly I hope you do.
“I certainly do not mean to suggest data literacy supplants what we think of now as literacy, but that it just might extend the set of skills required to be literate.”
That would be nice. But in this case, data literacy replaces literacy, as the required explanatory text is omitted, the data is treated simply as an object subject to de- and recontextualization, and the result is something that cannot strictly be read, but is used as the basis of a “pop test.”
Show me where literacy is here being expanded.
And the problem is not that this is fancy but useless; the problem is that it is fancy and actively misinformative, and indeed miseducational. It’s a do it yourself USA Today graphic. And it’s being celebrated?!
@Jon The educational point was actually to illustrate what steps might be included in a “pipeline mashup” – it was prep for a demo I did today, and will do again next week.
Just like referencing ideas, what I guess I should have done is add something to the description element created in the Yahoo pipe declaring the provenance of the population data and linking back to the original source; and in the spreadsheet I should have give an explicit reference/citation to the data source… but I didn’t (and I guess you didnlt make that sort of suggestion as a ‘how to improve this’ comment to the original post;-)
YES, there are all sorts of issues about taking data out of context and then representing it devoid of that context, but that wasn’t the point… (though it is the sort of thing I intend to get round to discussing on http://visualgadgets.blogspot.com )
Jon, I don’t think I can address all of your concerns here, you do have a point about context being “stripped away” in reuse that I think is a much broader issue than in data mashups.
I should also note that as far as I know I am more or less alone in applying the term “data literacy” (when I met Tony in Utah he didn’t remember coining it).
Maybe this approach to managing and reusing data will prove to be as odious as you suggest. A lot of mashups (cultural and data ones) do seem kind of pointless.
I first got interested in data mashups when I saw the Housing Maps application, which took Craigslist housing vacancies and applied them to a Google Map. What I found interesting was that the programmer was able to tap the existing data in these sources despite not being affiliated with either of them. It was also rumoured that the programming had been done in a single afternoon.
More recently I blogged about the UBC cycling map, a good model for making obscure data meaningful to me in my attempts to ride my bike more. There is simply no way this type of work could have been done without recent advances in “mash-up” style programming.
What I find exciting about Tony’s work in this area is he works with tools that bring the threshold of participation even lower – that even people with no programming skills and no budget can start to build resources like these. In a lot of respects, it reminds me of the early days of weblogging.
I hesitate to add this, but I did write an article on mashups a year or so back…
http://tinyurl.com/45f5ae
“YES, there are all sorts of issues about taking data out of context and then representing it devoid of that context, but that wasn’t the point…”
Um, what is the point, then? To do something that’s “kewel”? All surface and no substance? All process and technical trickery and no actual thought or context?
Again, Brian, the problem is not that this stuff is pointless. The problem is that it is actively misleading and misinformative.
And again, where’s the upside?
For what it’s worth, further thoughts here.
Hi,
Thanks for the nice post about data literacy.. I am really thrilled to see the nice post. I recently ran across a website called http://www.inspireyourgroup.com/books.htm where they offer a free pdf book called ‘Sure-Fire: The Most Successful Ice-Breakers & Group Games’ please use the link and download it the offers valid till October 31st
nice!