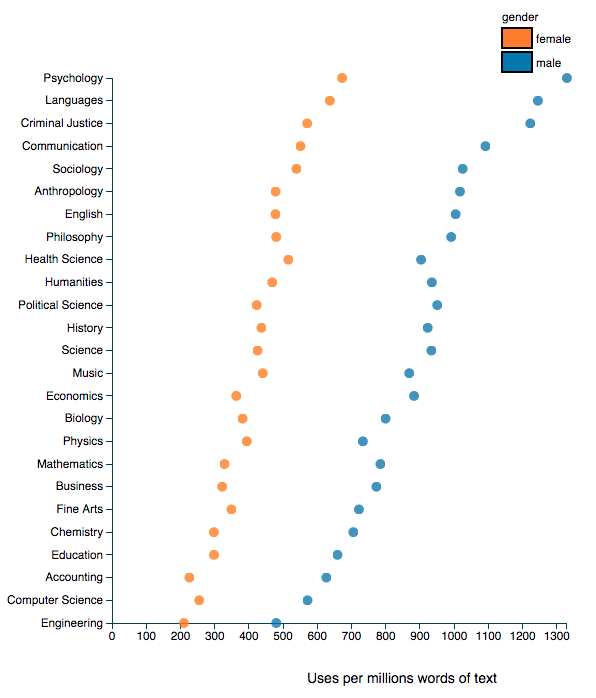
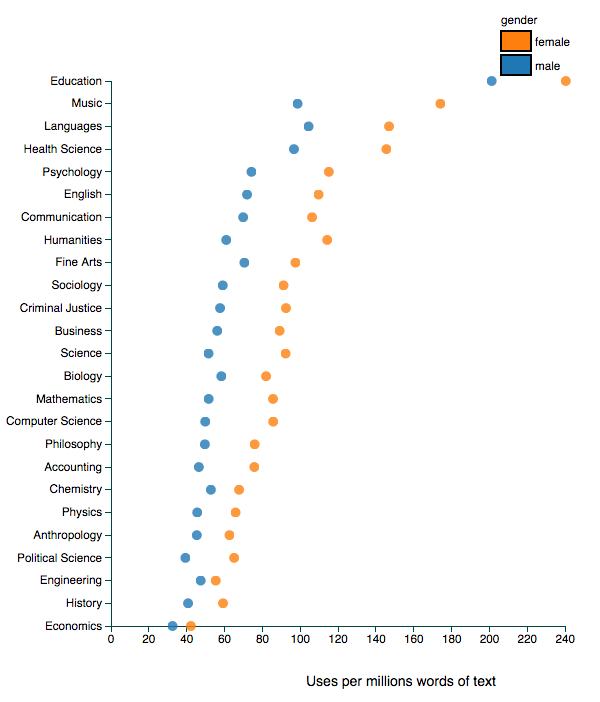
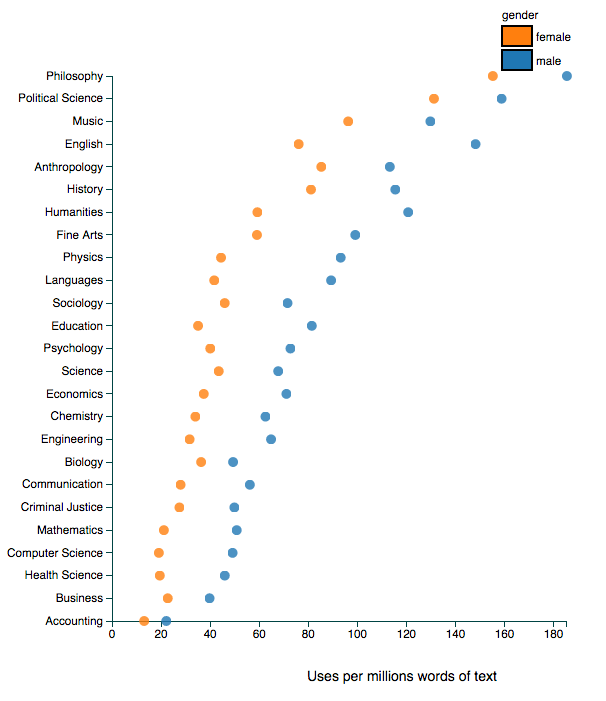
The terms external and independent evaluation are often conflated, largely because external evaluations are (wrongly) assumed to be more independent than internal evaluations. A good example is the evaluation of the LAUSD iPad initiative conducted by the American Institutes for Research, which is described in an EdWeek story like this:
An independent evaluation of the Los Angeles Unified School District’s ambitious—and much-maligned—effort to provide digital devices to all students found that the new, multi-million dollar digital curriculum purchased as part of the initiative was seldom used last year because it had gaping holes, was seen by some teachers to lack rigor, and was plagued by technical glitches.
To be fair, AIR calls their evaluation external, NOT independent. And the evaluation IS external because the evaluators (AIR staff) are not members of the organization (LAUSD) in which the evaluand exists. They are external also to the iPad initiative, the program itself.
 While a bit pedestrian, it is worth asking what is meant by independent so it is clearer how external and independent are not synonyms.
While a bit pedestrian, it is worth asking what is meant by independent so it is clearer how external and independent are not synonyms.
Using the LAUSD iPad example, is AIR’s evaluation independent? The first sense of independence would suggest the evaluation is free from control by any one outside of AIR and the AIR evaluation team ~ that the evaluation is not influenced by any one, including the LAUSD, Pearson or Apple. It is clear from the report that indeed the evaluation is influenced by the LAUSD by asking questions that are relevant and desirable to them, although there is no obvious influence from Pearson or Apple, the two corporations providing the hardware, software, and professional development. This is absolutely typical in evaluation ~ those who commission the evaluation influence the focus of the evaluation, and often how the evaluation is done (although whether that was the case in this evaluation is not explicit in the report).
A key to the influence the LAUSD has on the evaluation is illustrated in the description of the program milestones, the first of which is characterized as awarding the contract to Apple in June 2013. But it is clear this is not the first milestone as a LAUSD Board report released in August 2014 points to Superintendent Deasy’s manipulation of the bidding process so it would be a foregone conclusion the successful vendor would be the Apple/Pearson combo. AIR evaluators would have known about this. There is also no mention of the LAUSD’s refusal, when the project was rolled out, to reveal how much money had been paid to Pearson, a subcontractor to Apple on the $30 million first phase of the project.
Evaluators might argue that these matters are not the focus of the evaluation as framed by the evaluation questions, and that is likely true. The problem is that the evaluation questions are usually (and no reason to believe this wasn’t the case with the AIR evaluation of the iPad initiative) mutually agreed upon by the external evaluator and the organization contracting for the evaluation. That an organization would not want to include issues of malfeasance, transparency and accountability is understandable in many cases. A truly independent evaluation would necessarily include these issues, as well as other unanticipated circumstances and outcomes. The lack of independence is structural (in who commissions evaluations) privileging the perspectives of decision-makers, funders and CEOs.
The second sense of independence points to a failure for every external evaluation ~ external evaluators are in an immediate sense dependent on whomever commissions the evaluation for their subsistence and in the longer term sense if they wish to do evaluations for this organization again, or even other organizations who may monitor how the first sense of independence is treated in past evaluations. External evaluations lack financial independence.
And, external evaluations fail on the third sense of independence because the evaluators and the organizations commissioning evaluations of themselves or their programs are connected to one another, certainly financially but also often in an ongoing relationship with one another.
Whose interests are served and how?
 Because of the lack of structural and financial independence, external evaluations (as much as internal evaluations) emphasize some interests and serve some ends, while ignoring or bracketing others. In the LAUSD iPad initiative, the interests of both the LAUSD as a whole, the Board, and John Deasy are served both by what is included and excluded. The AIR evaluation provides a good descriptive account of the roll out of a major technology initiative, including issues with levels and types of use, quality of curriculum, and what worked well (the use of apps, for example). The evaluation could not be construed as positive on the Pearson curriculum content.
Because of the lack of structural and financial independence, external evaluations (as much as internal evaluations) emphasize some interests and serve some ends, while ignoring or bracketing others. In the LAUSD iPad initiative, the interests of both the LAUSD as a whole, the Board, and John Deasy are served both by what is included and excluded. The AIR evaluation provides a good descriptive account of the roll out of a major technology initiative, including issues with levels and types of use, quality of curriculum, and what worked well (the use of apps, for example). The evaluation could not be construed as positive on the Pearson curriculum content.
But by avoiding the inclusion of issues around the initial bidding process, so too are specific interests of Deasy, Apple and Pearson served. What does it mean that both Deasy and Apple were involved in manipulating the bidding for the contract? Put in the context of Apple’s aggressive marketing of iPads to schools, this becomes potentially an example of profit-making over learning. Apple’s last quarterly earnings claims more than 13 million iPads have been sold globally for education; 2 and a half iPads are sold for every Mac in K-12 education. The secretive partnering with Pearson, a company recognized more for making profit than making educational gains, should be an additional piece of an independent evaluation. Corporations whose primary interest is profit making and who mastermind programs and products deserve scrutiny for how their interests intersect with other interests (like teaching and learning).
Although there are few mechanisms for truly independent evaluations, professional evaluation associations and professional evaluators should be pondering how their work as either internal or external evaluators might be more independent, as well as developing strategies for conducting truly independent evaluations that are simply not compromised by the structural and financial relationships that characterize virtually all evaluations.
 A short radio interview this morning in response to a local school district decision on middle schools. Like some other interventions (DARE is a good example) the evidence isn’t strong for middle schools although there is still a commitment to the idea. While that’s not necessarily a bad thing one would hope that arguments for or against a middle school model are explicit, nuanced, and responsive to local community and school needs
A short radio interview this morning in response to a local school district decision on middle schools. Like some other interventions (DARE is a good example) the evidence isn’t strong for middle schools although there is still a commitment to the idea. While that’s not necessarily a bad thing one would hope that arguments for or against a middle school model are explicit, nuanced, and responsive to local community and school needs Follow
Follow