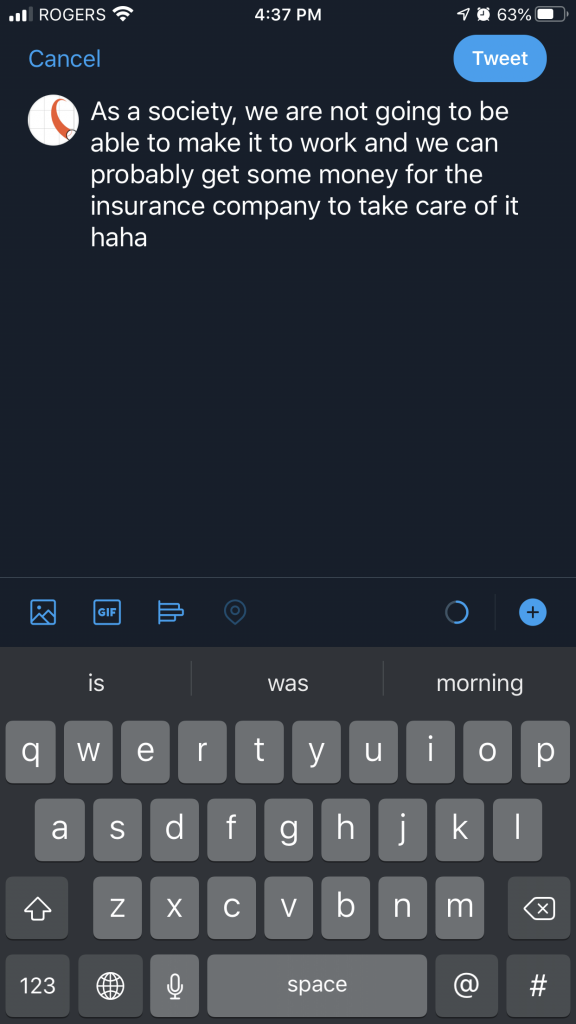
For this task, we are to take some sentence prompts, and use predictive text algorithms to generate a microblog. I used Twitter on an iPhone to generate my microblogs, with the beginning prompt of “As a society, we are…”. I did it several times, selecting a few different options from the algorithmically generated text:
Here are a few others:
As a society, we are on our own with the same amount of time we have to do our work for our family. I think I have a good idea about the insurance company.
As a society, we are not the same but I am so sorry for this issue but it was not going on at all until 5pm. I don’t want to be with you tonight because you are so busy with your mom.
As a society, we are going through the same thing as a family in the past. We can probably get some drinks or something to do next weekend. We have been in our past for the last two months.
The sentences were interesting, silly, ridiculous, and often confusing and nonsensical. At times they also generated hints of mirroring what people might be blogging about very recently. Is this just chance, or is this because the algorithm has been adjusting to what people are posting and blogging about over the last few months? Take the first one I posted, “we are not going to be able to make it to work and we can probably get some money for the insurance company”. In a global pandemic, this kind of sentence, or the two separate thoughts within the sentence, very likely could have been typed by many people. The second one, “we are on our own … we have to do our work for our family” could be seen as echoing similar pandemic related thoughts and concerns. The third one, “I am so sorry for this issue” could be seen as related to the recent Black Lives Matter and Me Too movements, with many people expressing this kind of sentiment. The fourth one, “we are going through the same thing as a family in the past,” could also be pandemic related, with people expressing similarity to this issue with previous pandemics or hardships.
On the other hand, I could be unintentionally putting together sentences that reflect current events that would not be auto-generated by the algorithm, simply by putting together the words offered by the algorithm in unique configurations. How much of these sentences are thoughts I intend to, or want to, express, and how much is shaped by what the algorithm presents? I suspect most people do not write sentences solely from predictive text (I certainly don’t), but I do often use it to write the word I intended to write if it is suggested. Do I ever let it write a word that has a similar meaning or usage that I personally wouldn’t have chosen? I’m not sure – but it certainly seems possible, in which case the algorithm is actually subtly changing my voice through this text medium. What does that do on a societal level?
I would say that none of these sound particularly like me, although one thing that stood out was the “haha”. I do most often type “haha” instead of “lol” or other expressions when I think something is funny. Is this personalized for me, or is it just a coincidence? I also wonder if this is an iPhone specific predictive algorithm, or is this a Twitter algorithm? Is it specific to my tendencies at all, or my local region, or country, or is it worldwide? None of the content of the messages seem specific to me, or seem similar to things I have written, but I also do not regularly post on Twitter, so perhaps it just has a limited amount of data to use to give suggestions to me.
It also doesn’t appear to be academic or professional writing, it does give the sense of being more casual in it’s influence. It makes me suspect that the algorithm learns from other microblog posts, but it is hard to be certain. The fact that it doesn’t seem to capture an individual’s ‘voice’ when writing is interesting. Does this make it get used less than it would if it was more personalized? I suspect yes, but it also raises the question of if it ends up acting on a large scale to homogenize our writing and self-expression. Does it also then influence our writing outside of this medium? Do the types of words and phrases that get commonly suggested to us end up becoming the way we speak and write even when not using predictive text algorithms? What affects would that have? The predictive text that I saw seemed to be very standard ‘semi-professional’ English, meaning no slang, few contractions, etc. For cultures that have other styles of writing, does this work to create bias against their communication style, or work to diminish or eliminate their semiotic style? Who chooses what text is included in the predictive suggestions, and where do they come from? What are the decisions behind what gets included, and why? If these algorithms become more widespread in arenas beyond microblogs and text messages, will they begin to affect how we write and think in those spaces? For example, if predictive text were to become widespread in educational contexts, especially in cases where children are learning how to write, there may be an outsize influence on how they shape their writing and thinking. On a societal scale, predictive text could end up altering how an entire generation thinks and expresses itself, and we have no idea the outcomes that this might cause.
I think predictive text can be very useful, and it can speed up our communication and reduce frustration when typing on small keyboards like on smartphones, but the potential subtle influencing of our thinking and writing needs to be considered. Very much like the discussions of other big data algorithms in the readings and podcasts this week, by Dr. O’Neil and Dr. Vallo and others, I think it is very important for algorithms to be open-sourced and made much more transparent. I had never before stopped to think about why the predictive text suggests certain words to me on my iPhone, or what that might do to my thinking. The only way to know if there is unwanted bias or unwanted influence occurring because of algorithms is to know how and why they operate the way that they do.