In Task 9, we are analyzing a network (graph) database generated from the previous Task 8 – Golden Record Curation Quiz.
The initial graph I was presented with, after loading the data file:
As you can see, without interpretation, analysis, or manipulation, the graph is of little use. The visualization might be interesting in the sense that you can tell how interconnected everyone’s choices are, but beyond that surface thought, there is little of use you can tell from a zoomed out view without manipulation. I think this is a good insight into most graphs and datasets. Their usefulness depends on manipulation, interpretation, and analysis – all things that both create meaning and change meaning. One then must know the motivations and intentions behind the analysis, interpretation, or manipulation to fully contextualize the resulting conclusions. It is also important to note that this graph itself is not “raw” data. The data has already been manipulated by forming links between each song selection, and then creating groups based on the strength of each song selection. By default when I loaded the data, the individuals were also highlighted and the songs were not, giving initial implicit assumption that the individuals and their connections are what is important versus the song choices.
Looking at the group I was placed in, group 1, I pulled the graph apart to see connections more clearly:
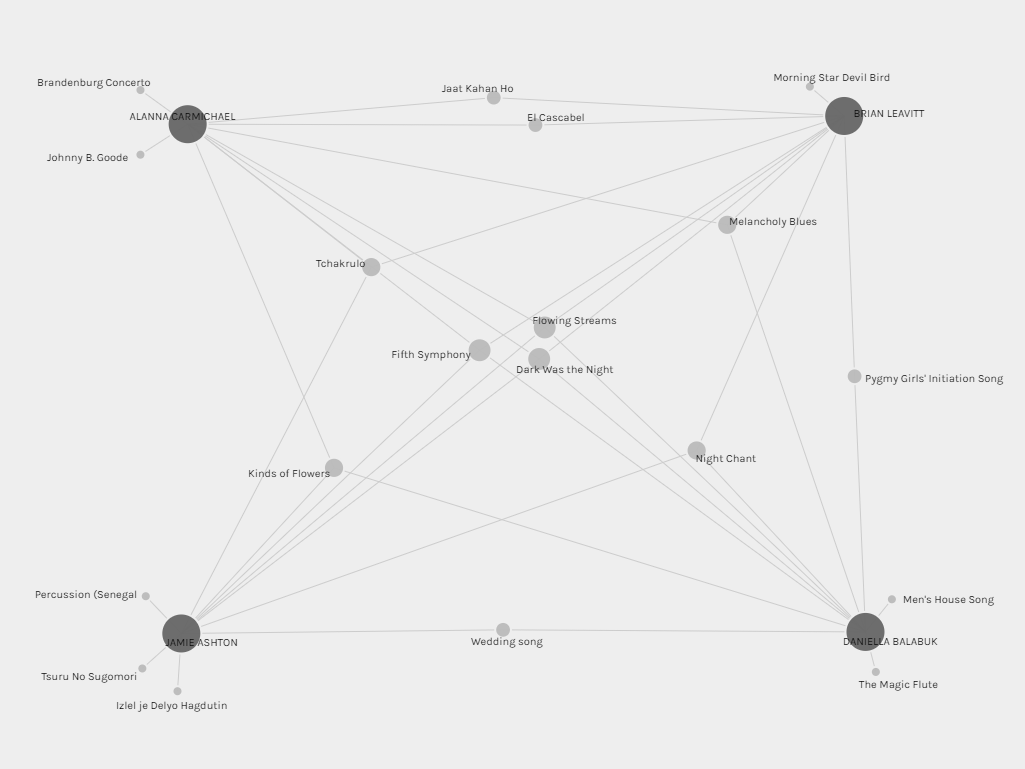
In this group of four individuals, you can see that I have one song that is not directly connected to the group, two of the others each have two, and one has three unconnected songs. We all share four songs, and there are several songs connected by three and two connections. One interpretation of this is that I am more similar to the others in this group than they are to me, and I could extrapolate from this that I am the “center” of this group. I don’t think this would be an accurate interpretation, however. You could also count the number of secondary connections, in which case Daniella would be seen as the “center”. This all implies that there is a “center”, and that it is important, which would be an assumption and decision made by whoever is interpreting the data.
I also looked at the one song that I did not share with the rest of this group, “Morning Star Devil Bird”. I looked at all of the connections that existed to that song, seen at the top right of this graph:
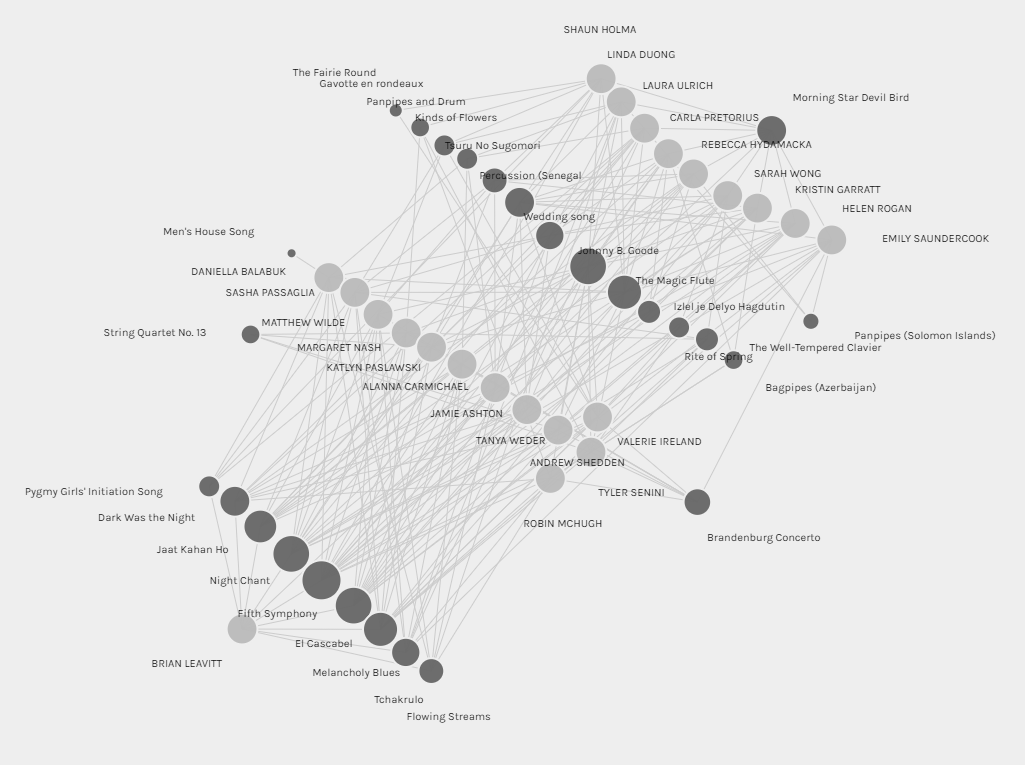
If it isn’t completely clear, the line of people in the top right are all directly connected to that song, and there is also a line from that song all the way to the bottom left where my node is. I pulled the nodes apart and organized them to see the links from my other song choices as well. What I find fascinating about this is that there are so many connections between people who are connected to non-“Morning Star Devil Bird” songs I chose, and people who also chose “Morning Star Devil Bird”. Perhaps this is just a result of a relatively limited set of songs to choose from, and secondary or tertiary connections are inevitable in such a small sample size. It does seem to imply that this one song choice connects me to a completely different set of people than the rest of my song choices, but those people are also fairly similar to people who are connected to my other song choices. If this were a graph of political opinions, this would be the one outlier belief where someone diverges with their political party of choice.
What does it mean to group people at all? Considering the group I was sorted into, we all only have four songs in common. How much of a group are we when we all collectively only share 40% of our choices? There is also no strength of preference taken into account. What if my very favorite song was the one that is not directly connected to any of these group members? Should I still be in this group? Alternatively, all non-choices are considered the same, but I could have several songs that I specifically dislike, and perhaps they should be included by the algorithm to make sure people are not linked by songs they specifically dislike. This graph also assumes that all song choices are intentional and complete. Each individual was required to select 10 songs, no more, no less. There could be some (I am one) who only wanted to select 4 or 5 songs, and the rest were relatively meaningless. How can people be grouped upon choices they did not want to make? Conversely, there could be some who wanted to select additional songs which would have changed their groupings, but were unable to by the limits of the data collection method.
When people are grouped by algorithms, there is no choice. The assumptions of importance by the algorithm creator are rarely questioned, and are taken as unbiased fact. What does this do to people who are grouped in a way that they would strongly disagree with if they knew why they were grouped in the way they were? Grouping by algorithm also tends to subtly reinforce sameness over time. If your life is shaped by algorithms that push people with similar likes, interests, thoughts, and opinions together, an important part of society is changed. Opinions are reinforced and made more extreme, instead of tempered and reexamined. Exposure to new experiences, cultures, and contexts are slowly limited. A large part of this issue is that most people do not understand how algorithms work, even if they are aware that they are at play in the daily technologies and systems they interact with. Algorithms also tend to be proprietary and secret – they are often used to generate vast wealth, and so are well-guarded intellectual property. If we do not want to cede control of our lives to the unknown motives and biases of those who create and utilize these algorithms, they must be made public and open-source.



