The experience of completing the task this week was the polar opposite of Task 8’s for me, which was strange as these two tasks are really inextricably linked. As I worked through the module’s theory component, I suddenly felt at home with words such as “matrices” being used. As a science graduate, mathematics feels very much like a safe space and a tool I can rely on to help reveal the truth about relationships in data. Or can it?
It was with much enthusiasm that I opened the data set sent by Ernesto in Palladio. I was fascinated by all the facets and groupings available to toggle and filter the visualized networks with. Just a few seconds were needed each time to reveal a new and unexpected connected network between the musical tracks, curators and groupings. Each one calling out for careful further inspection to make sense of the interesting visuals taking over my screen. It also meant a lot of crosschecking with fellow curators’ posts on the reasons for their track selection to paint a richer story of the networks panned out in front of me.

The very first network I’d like to share was one created with just myself and Kristin’s track choices. Even though I had read over her post last weekend describing her curation, I was very surprised to see that we in fact had picked nine identical songs (you might be wondering whether we were comparing notes on the sly during our selection process but I can guarantee you that we weren’t). Judging our song selection solely by the visualization of this network though would tempt one to think that our analysis and curation of the songs must have been based on similar criteria.
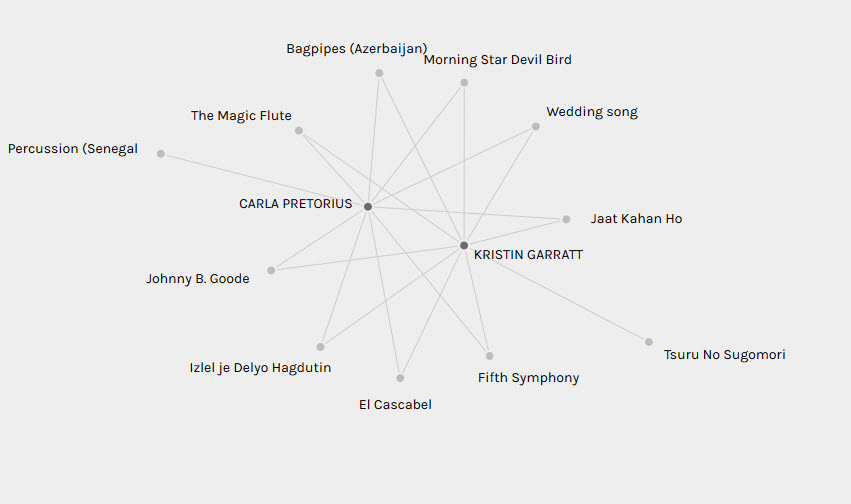
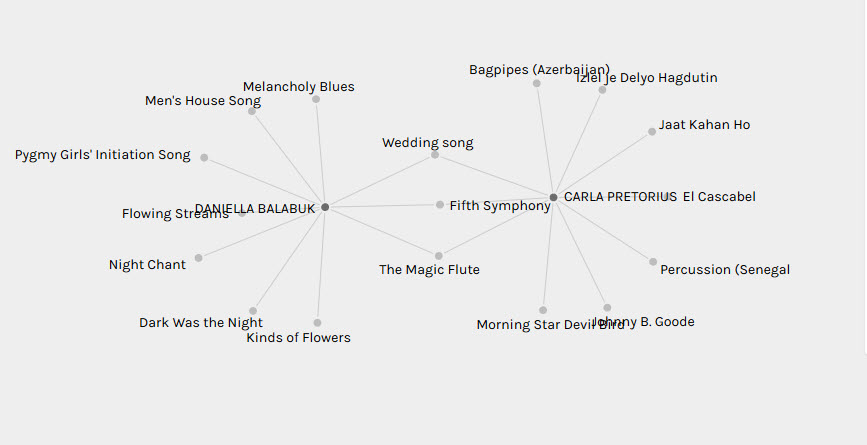
I distinctly remembered though that Kristin had followed a meticulously thought out process in the way that she selected her songs. She eliminated songs that had similar sounds from her list and she tried to represent the different continents in a more equitable way. In contrast, my own criteria for song selection was based solely on a song being able to evoke some kind of emotion in me. Vastly different approaches resulted in almost identical song selections. This was fascinating to me and highlighted the risk associated in interpreting data without considering the context from which that data came. A first glance of the connected network formed between Kristin and my selections would have rightly led one to conclude that we placed emphasis on similar songs but it does not reveal in any way the reasoning behind that selection and emphasis (which could only be gleaned from our blog posts). Fascinatingly, this bias could also be confirmed with the network graph created between Daniella’s track choices and my own. Like me, she also chose tracks solely based on emotional reactions but in this case, we only shared three identical track choices.
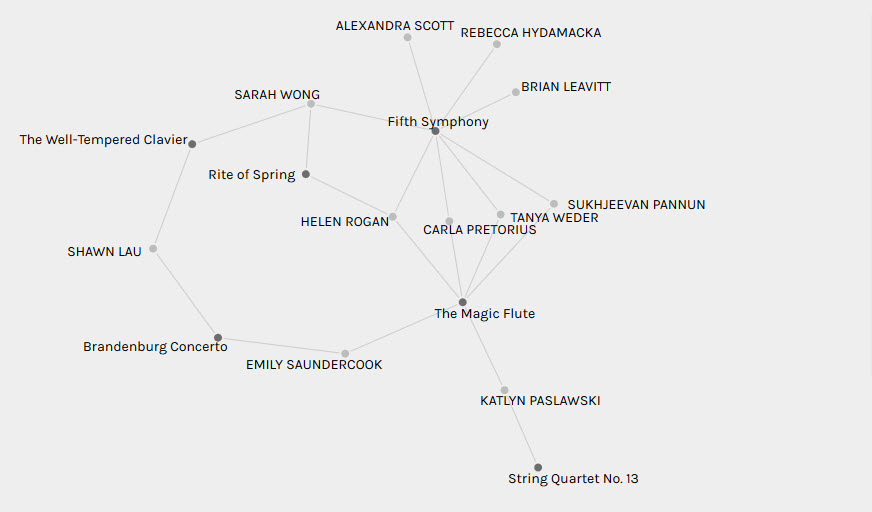
The other graph I wanted to show-case was a multiplex network created between the most popular track curated (Beethoven’s 5th Symphony) and one of the least popular tracks (the panpipes track from the Solomon Islands). Only two curators had selected both of these tracks (Rebecca and Sukhjeevan) thus signifying the critical role they play in connecting these two networks. In contrast, the track I rated as my favorite (5th symphony) and least favorite (Johnny B. Goode) had a multitude of curators that had selected both songs.


I also wanted to look at the network formed between the eight classical tracks of the Golden Record and the choices in curation within my group since many of us had commented on there being too many such tracks perhaps included on the Golden Record. This revealed that the 5th symphony was the most popular choice of classical song and on average most curators in my group had selected two classical pieces with the most popular combination being this track with the Magic Flute track. Most interestingly though, the three curators to have only selected one classical track (Brian, Rebecca and Alexandra) had all picked the 5th symphony to form part of their curation. I think this says something about how pervasive the 5th symphony in fact is in terms of its reputation as a true piece of musical mastery but again this might just be my interpretation.
I think this exercise was useful in revealing interesting similarities in the choices made among all the curators in their selection of songs. However, it’s also very clear that one has to be careful in reading too much into the choices made as the reasons for selection can clearly be vastly different, which adds a different dimension to how one views these networks.