
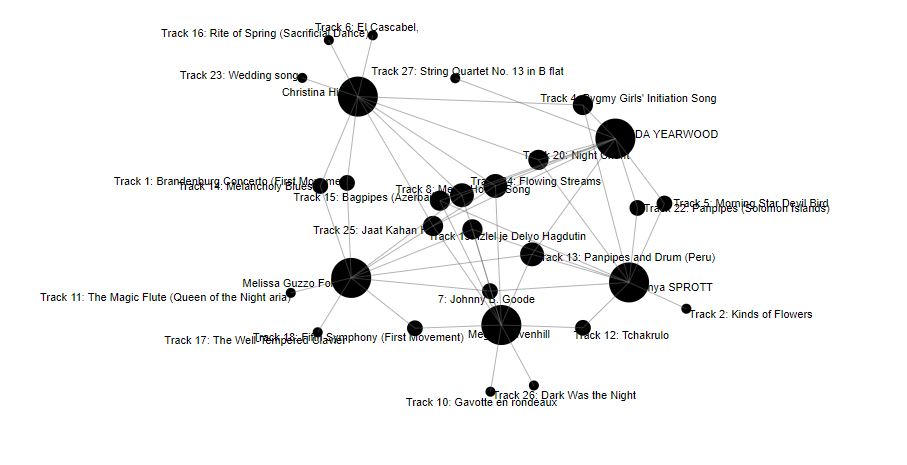
This was the community that Palladio’s algorithms placed me in. Network graphs such as these often use the term “degrees” to identify connectivity, so I’m going to use that, hopefully correctly, in my analysis. Of the songs we all selected, I created a table to try to organize the level or degree of connection and bolded my own selections to see how my choices matched with others in my community.
| 1st degree (only 1 person selected it) | 2nd degree (2 people selected it) | 3rd degree (3 people selected it) | 4th degree (4 people selected it) |
|
|
|
|
In our community of 5 curators, we had three 4th degree nodes where 4 out of 5 of us picked the same song. Of those 3, I was the outlier in 1 of them, meaning the other 4 chose it (track 13: Panpipes and Drum (Peru)), but I did not. It’s interesting because in my original criteria, I noticed that there were quite a few songs of the 27 that featured panpipes, so I chose to select only 1 (Men’s House Song). My criteria for that was again different sounds. The fact that the Men’s House Song was one of our 4th degree songs was also interesting. I had chosen it from all the other panpipe songs because of the emotions it evoked in me, but would that we the reason that others chose it? Especially when others chose other songs with a similar sound or instrument being used? Why would they all have chosen the 2nd panpipe song? Was it more of a focus on geographic representation over the sound itself? This, the data does not reveal. I could assume that searching for different sounds was not a priority in my community as there was also two other panpipe song selected, although they were only a second degree. It appears that my community was attempting to have either geographic or cultural diversity, and it was interesting that 2 of us chose Melancholy Blues while 2 others chose Johnny B. Goode which are similar culturally and stylistically.
Essentially I feel that, like the algorithms that track numbers of links back to the same page to provide better search results (Code.org, 2017), the algorithm in palladio simply looked for the number of matches. This was all the information that we had given the program, so without more detail like rankings, key terms, categories etc, it couldn’t possibly know why we picked specific songs, or didn’t pick others, just that we had picked them. Just like search results, the more links to the same songs, the more likely you were to be in a specific community. I would be curious how it ranked the connections. Did it require a certain value for the number of connections? Or a certain degree of connection a certain number of times? And what does this tell us, without the context of WHY the song was chosen. I find these questions fascinating.
References
Code.org (2017, June 13). The Internet: How Search Works [Video]. YouTube. https://www.youtube.com/watch?v=LVV_93mBfSU&t=212s