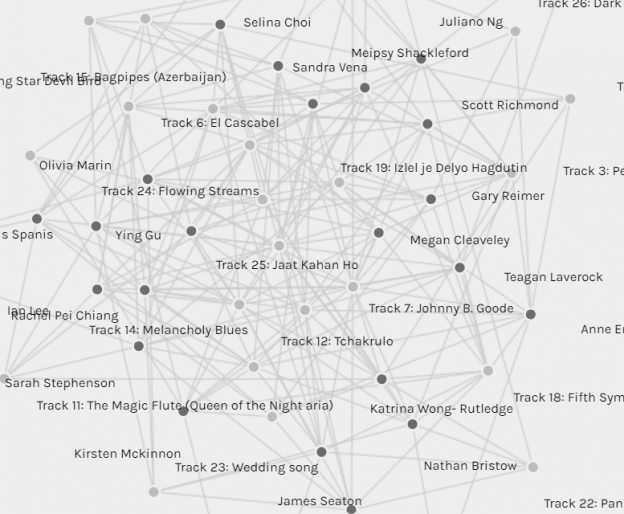
A brief introduction: I was tasked – along with my classmates – with curating a list of ten songs from NASA’s Golden Record (see post). Our professor collected this data and produced a graph to visualize our selections. The graph is shown below, with the lighter nodes representing the songs scaled in size relative to the number of times they were selected (denoted by edges attaching songs to the darker nodes which represent each classmates). For example, the song “Johnny B. Goode” was selected by all 23 classmates and is therefore represented by the largest circle (node). That song’s node is also much closer to the center of the graph compared with those rarely-selected songs with few edges, shown on the outskirts. The ten songs set for inclusion would then arguably be those with the highest number of selections – or highest degree of connectivity, according to Systems Innovation (2015).
Right click and select “open image in new tab” to view a larger version of the graph
Subset groups were also formed based on similar selections. I have included a graph showing my personal group. Note that although we selected enough common songs to be grouped together, this is no way expresses how similar our reasonings were.
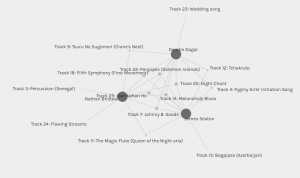
Right click and select “open image in new tab” to view a larger version of the graph
My reflection on the process and results:
First and foremost, I think that there is so much more to consider when performing such a curation than simply selecting your own personal list of ten. One of the big considerations I had when selecting my own list of ten was attempting to avoid repetition of similar songs. Even if all of my classmates had the very same general thought process, if half of us selected one song and the other half selected another (with the two songs being considered the most similar to each other), both songs would likely make it into our curated list, an outcome none of us would really be in favor of. If you take the same idea but apply it to a group of four or five similar songs, if all classmates hold the same idea of selecting one of those songs and end up splitting the vote too many ways, none of those songs ends up being selected. In both cases, the curated list isn’t reflective of the collective intentions of the group. Another issue is the question of weighting, as there is no way to emphasize the importance of a particular selection (or lack of selection) in the current selection process.
Due to these perceived shortcomings (along with others), I am proposing three methods which could help make the curation process more representative of the collective will of the curators.
- Ranking (true majority rule) – as addressed by Dasgupta and Maskin (2008) in Scientific American (see here for a full explanation), ranking candidates in elections is a more accurate way of reflecting the collective will of the people. In deciding between any two candidates, the selection would be based on a direct comparison between how many ballots they ranked above each other in. This may be quite complicated to implement when selecting a larger subset of choices, however.
- Ranking (rank-order voting) – also mentioned by Dasgupta and Maskin (2008), this is the system employed by the Heisman Trophy selection committee (“Heisman Trophy”, 2021), in which choices are ranked and points are awarded accordingly (in the case of the Heisman, voters make a selection of first through third place, and those candidates receive three, two or one points as a result). In this case, each curator would rank the songs one through 27, with the inverse value being assigned (a first place vote receives 27 points, and a 27th place vote receives one point, etc.). Those songs awarded the highest number of points would then be included.
With the current curation system, all ten selections were considered equal (and the same could be said of those not selected). However, curators most likely had stronger feelings about some songs being included over others, and either ranking system would better reflect that than the status quo.
- Iterative voting – selecting one song at a time, and after each selection is made, voters would have a choice to adjust their voting strategies. This could be done with either a single vote each selection round, or could still be done using one of the ranking systems mentioned above. This would help a lot assuming that most curators voting were attempting for a sense of variety in the curation, or were hoping to include songs from different personal groupings. Personally, there are songs I would not vote to include if similar songs had already been slated for inclusion, so I know this would help better reflect my choices.
In the end, curating such a list will never fully satisfy all parties involved. However, with some adjustments like incorporating aspects of the methods proposed, we can do a better job of supporting the rationales behind the selections.
References
Dasgupta, P. & Maskin, E. (2008, October 6). Ranking candidates is more accurate than voting. Scientific American. https://www.scientificamerican.com/article/ranking-candidates-more-accurate/
Heisman trophy. (2021, March 14). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Heisman_Trophy&oldid=1012034262
Systems Innovation. (2015, April 19). Network Connections. Retrieved from https://youtu.be/2iViaEAytxw