This was another fun task to play with. I had tried out a few of these predictive text completions over the last few years as they popped up on social media as prompts (one of the most memorable being Harry Potter and the […]). I was curious to see what my predictive text would do with these prompts, which were about more ‘serious’ content rather than playful content that doesn’t call for literal meaning. Whilst watching the videos for this task, I also found it interesting to see that the author selected which of the three predictive words to use. In some prompt activities I’ve done you are explicitly directed to only use the middle option of the three that are offered. So, with some choice at my discretion, I proceeded into this task!
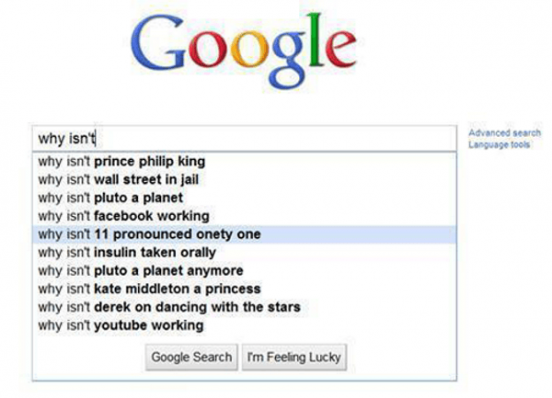
Sidenote: The featured image of this blog is the predicted text generated by google (autocomplete) when you search something, and it’s one of my absolute favourite things to play with and such a nice example of predictive text based on huge data inputs.
Predictive Sentences
I decided to write these prompts in a WhatsApp message, because it was one of the few places I could think of where I could type with predictive recommendations on my phone. Here are the sentences that were generated:
- My idea of technology is to make it work for the next generation and to get the perfect balance needed to make it work
- Every time I think about our future in the morning we have a happy day
- As a society, we are all good at the same thing and we can do a lot more
- This is not my idea of a window or a place where I am going
- Education is not about the new year of education but the next few years of school
My phone doesn’t offer recommendations for emojis, gifs, or other media so you can see that these sentences are restricted to being text only. Looking at the sentences, a lot of the content/language relates to time and place, which makes sense when considering what I primarily use my phone communication for. My academic writing happens on writing software, my work communications happen on slack on my laptop, and my phone is mostly used for correspondence around organising meetings, sending greetings and wishes, or communicating logistics with friends and family. Whilst topics such as society, education, futures, technologies, and ideas are a part of the social landscape I am in, these usually happen in spoken format rather than written format so I don’t think my phone text algorithm had a lot to work off of.
Statements like these are possibly found in more informal, opinion based places where people are speaking using stream of consciousness rather than planned speech. This could be in places like personal blogs, or in a podcast, or in a social media post on twitter or Facebook. The statements are quite different to how I normally express myself for a number of reasons. I usually use a lot of punctuation to express pauses and emphasis, and make use of emojis for tone. I am also an individual who spends a lot of time constructing statements to make sure that they make sense and clearly communicate my core idea, which these sentences don’t really achieve well. This also detracted from these sentences feeling like my voice, because I could never see myself producing these types of statements. So, the content, the structure, and the tone of the sentences didn’t feel like something I would write.
Following this, I wondered if my predictive algorithm shifted based on the app/platform I was writing in and the data it gets from me so I decided to test this by trying out the predictive sentences in my Facebook app instead. These are the sentences generated through predictive text written within the Facebook messenger app:
- My idea of technology is that we can get it sorted out and we can make it work
- Every time I think about our future I think it’s just an hour before we can get the same thing done
- As a society, we are the best for the first time in the world
- This is not my idea of what the world needs
- Education is not about being able to help with stuff
When first reading these, I definitely thought that these sentences, due to their vagueness and shortness, felt like a weird combination of political statements and those inspirational quotes usually shown over a pretty background picture of an ocean. However, they are a little more aligned with sentiments that I may have, even if they are not expressed in my normal ‘voice’. This may be due to the fact that Facebook is where I share a lot of political information, where I manage/run/participate in academic research networks, and where I network with a more professional circle rather than a private one. These sentences also definitely have a different tone to the ones written on WhatsApp, but they are still equally far from things I feel like I would say or the way that I would write. So whilst they are slightly closer to my ideas, they are still not the way I would frame or convey them.
Analysis
On both platforms, the generated text did not reflect ideas/sentiments that I held, nor was it written in the tone or with the language and intonation I would usually make use of. This was compounded by the fact that my writing, talking, or thinking on the subject matter of the prompts is usually far more structured and formal because I consider them important points. WhatsApp’s sentences didn’t feel like they reflected my ideas, or my way of writing, at all. Facebook’s predictions vaguely reflected my ideas on the topics at hand a little more closely, but did not produce text I would consider I authored in any way.
Algorithms writing things is definitely starting to infiltrate our public spaces and daily lives. AI is already being extensively used to write articles in journalism. Or, watch this trailer for a science fiction movie written by an AI in 2016 (specifically, a recurrent neural network which named itself Benjamin). He was fed the scripts of dozens of science fiction movies including such classics as Highlander Endgame, Ghostbusters, Interstellar and The Fifth Element and came up with this:
Two years later, Benjamin wrote and directed another piece:
It is always an interesting experiment when text algorithms get involved in creativity, but when they start participating broadly in public writing spaces there are different implications. In this task, text was predictively generated based off inputs I had given it, but it didn’t accurately reflect any of my opinions or ideas. The outputs shifted apparently based on the type of text it had been gathering data from. If these predictive texts were used to express my thoughts on things, especially if I did not get a chance to edit them or confirm their accuracy, it would be a poor representation of my opinions and I wouldn’t consider them to be authentic and I wouldn’t want to be accountable for them. They are also just vague and difficult to understand, not really carrying much meaning that can easily be accessed without extensive interpretation. This brings us to a point where we can consider two perspectives. One in which an algorithm produces text that isn’t problematic, and one in which it produces text that is.
In situations where generated text isn’t problematic, such as the sentences produced from using the predictive text on my phone, there is still a high chance that it will not necessarily make sense. This means that even where an algorithm has interpreted the text data and generated sequences that are consistent with the input, what it produces may not frame the information in a way that is relevant or easy to understand. If the text successfully reflects a core sentiment (or voice) of an individual, it still may not be written in a way that can be applied well. This becomes even more complicated when extensive datasets are drawn from large groups of people, and individualism is erased in place of an AI trying to compile text that represents a group consensus. Predictive text will only produce common words, not meaningful words, and thus may end up with some very strange representations of groups because the same word may be used in two completely different meaning contexts. Another issue here is that it freezes an individual in time by working only off old data and not off evolving inputs from associated thoughts and experiences that go beyond the limits of text. Humans and the worlds we build for ourselves are constantly adapting and responding to new stimuli, and whilst we do work off a database of our own experiences we are capable of producing new ideas that break away from any pre-existing standpoints. I am not sure how well text algorithms would be capable of capturing this innate flexibility in the content they produce. So from this perspective, predictively produced text shared in public spaces can be problematic due to it being incoherent, outdated, or falsely identifying commonly used words in groups without their associated contexts.
However, the stakes change when we move from individual and group sentiments to text that governs, shapes, and leads our societies. Imagine an extreme situation in which a predictive algorithm was fed textual information about education and was then expected to generate policy. Or a situation in which algorithms are fed information about populations to generate governing laws or constitutions. Text in public spheres are meant to represent human ideas, convey information, and guide actions. If we can already see that in low-stakes environments, predicted text is not clear in its meaning or representative of the original dataset it worked from, this will have bigger consequences in high stakes environments. Algorithms cannot understand context, or combined/complex meaning, and thus even an accurate dataset may easily output inaccurate statements that the original speaker wouldn’t want to claim. Various spheres of society rely on text to carefully construct and communicate information that is framed and released with a lot of planning and intentionality, and predicted texts would create a degree of separation that could be problematic or even exploited. When a person says something that unsettles others, we can ask them to justify it or to explain their logic. This isn’t possible with predicted text, and we already saw how unsettling it was with the golden record task to see a final output without being able to identify process and causality. If public texts are not directly linked to an individual/organisation it will be difficult to determine why something was said, who said it, and who is accountable for changing or implementing it. This means that predictive text also carries potential issues around authenticity, authorship, and accountability as well.
Video Library
How does my phone even do the thing it does? And does a predictive algorithm manage to capture the voice of Bruno Mars? Answers below…




TYLERSENINI
July 24, 2020 — 3:27 pm
Hi Jamie, thanks for sharing! I enjoyed the videos you posted to go along with the Task. I think on twitter I tend to speak like this all the time! My phone auto changes my words when im trying to text sentences which to me is aggravating.
Jamie Ashton
August 5, 2020 — 5:22 am
I find autocorrect a very frustrating experience at times, and a time-saving dream in other moments! Technology so often seems to go in two directions 🙂
Tanya
July 24, 2020 — 4:17 pm
I never heard of Automated Journalism or these AI screenplays before reading this post. Thank you so much for sharing them. As far as the movie goes… interesting but definitely hard to follow or make sense of (and that is after people have added nuance like non-verbal communication). As you point out, meaningful communication is so multi-faceted that it would be extremely difficult for an algorithm to get that right. Think we are still a way off of a generated text being able to create a creative piece that engages human emotion.
Really loved your point about “predictive text also carries potential issues around authenticity, authorship, and accountability”. Absolutely! Text embeds so much beyond words and punctuation. I think it is very important, as you’ve pointed out, to consider the differences between an AI being able to make a sentence that follows grammatical rules, and one that makes sense and captures intelligent intent. This is untangling the meaning from the mode of communication.
I do think it is a dangerous game to let computers write articles that are non-distinguishable from human made ones. Will the algorithm learn to have a different agenda? What insights and interpretations of the data are being presented to the reader if there is no human involved and what could be the real-world impact of that? We saw in the Voice-to-Text task that technology misunderstanding language is very common but what happens if the errors are being intentional made to deceive? I have seen many films of dystopian futures around machine learning that it is easy to imagine how this might happen.
Thanks for a very interesting read!
Jamie Ashton
August 5, 2020 — 5:23 am
Hey Tanya,
You bring up a lot of good points. I think the question then becomes whether an algorithm is even capable of something like an agenda, or if the agenda is from the person creating the algorithm! It’s gonna be an interesting, and sometimes challenging, future ahead when it comes to conversation about algorithms and text… and being informed about what is happening is going to be a huge part of it.
Thanks for the thoughts!
SASHA PASSAGLIA
August 11, 2020 — 9:53 am
Hi Jamie!
I thought it was really interesting that you decided to compare the two different platforms and their ability to generate the predictive text for your input. I think that must have to do with your research background 🙂 You made some excellent points in regards to the type of work you would normally do on those platforms and how the system generated different texts. I find that when I’m emailing via google, it often will predict my next sentences, “I look….(forward to hearing from you,)” etc. While this can be helpful, it also makes you stop and think about how our writing is being taken away from us. Though it’s supposed to be there to make our lives simple, it seems as though the AI within these platforms is doing the thinking for us – and I believe it’s for this reason that I enjoy pen to paper (as I remember you do as well) to write my thoughts and ideas down versus the computer. Thanks for another excellent post!
Jamie Ashton
August 12, 2020 — 11:29 pm
Hey Sasha!
I like your framing of the fact that writing is being taken from us. It made me think of this beautiful rant from Stephen Fry https://www.youtube.com/watch?v=APSGYIuOu9k
Language is such an incredible thing, and the way we write it and build our sentences can bring across a lot more meaning than the words themselves. It’s a joy to write and form words, and I don’t really want it to be taken away to be honest 😀
Thanks for a thought-provoking reply!