#1: Maurice Broschart’s Twine Task– https://blogs.ubc.ca/etec540texttech/task-five/
Reflecting on this selected link, I believe that I was drawn to Maurice’s post due to my own experiences working with Google Docs and linking in the same manner that he shared. In my professional life, I often use links within documents to share multiple sources of information or contextualize learning for my students. What I never considered was the fact that this is actually creating a hypertext that my students and I interact within without a second thought. It became second nature for those individuals who were raised as digital citizens and practice digital literacy on a regular basis.
These documents that are linked may seem to be one continuous text, but really demonstrate the concept of parallelism, as discussed by Nelson’s (1999) writing. With the ability to rapidly access information from multiple authors without necessarily changing our mindset between readings, the reader may be unintentionally ignoring the intention of a text and making objective comparison impossible. With the expansion of the Internet network and the complexity of node connection, it is easy to ignore the intentions of online texts in hypertext and use them to serve our own purposes. I think of writing an academic paper in my undergraduate as an example. I would often use the references section to find related journal articles, but use only a sentence or two to reaffirm my position rather than considering the full context of the research. The hypertext network made it easy to jump from text to text without changing the perspective lens that I was using to critically examine the text. I can fully understand and appreciate Nelson’s (1999) perspective that intertext relationships need to be visually seen in order to explain, comment or disagree with in an informed manner, even if this reality is incredibly challenging with today’s largest hypertext, the Internet.
Nelson, Theodore. (1999). “Xanalogical structure, needed now more than ever: Parallel documents, deep links to content, deep versioning and deep re-use..” Online.
#2. Johanna Bolduc’s Potato Stamp Task- https://blogs.ubc.ca/boldjo/2021/10/04/assignment-4/
The reason that I selected Johanna’s post for my linking reflection was the difference in the way that we chose to approach the task. For my print, I chose to cut in relief into a single potato, whereas Johanna imprinted each letter into its own respective potato. Looking at the Clement (1997) reading on the evolution of printing and eventual mechanization that lead to mechanically printed texts, I felt that I had taken a much different perspective on the manual printing process.
When approaching this task, I never considered carving the letter into multiple potatoes or sections, only that I would be doing a single word on the single stamp. I believe that this assumption of the best method to approach the task stems from my relationship with the text, in the sense that it is simple for me to generate and print text using technology. While typing on a computer or smartphone is creating the same text as the use of matrixes and pressing, there is a disassociation between the process since the labour and the product. Additionally, word processing software and algorithms that assist with corrections often deal with the combination of letters only as a single word rather than individual elements, something that I have also incorporated into my method of thinking about the creation of text.
My approach to this task was in contrast to Johanna’s. She took an approach that echoed the development of the Gutenberg printing press that used imprinted type blocks to impose the text onto the paper. Celement (1997) makes note that having type to complete a full book would be incredibly expensive and the type needed to be reused to make the process practical (pg. 14). This revelation in reflecting on the post was that my “potato type” would be incredibly ineffective in a printing press due to the singular nature of my selected word, whereas Johanna’s approach would be much more practical due to the multiplicity and fluid nature of the individual letter types. We both reflected on the time-consuming and patience-requiring nature of the process, but my approach would actually require a significant amount more time and effort. This realization made me examine my relationship with text and how I take the production of text for granted through the usage of technology.
Clement, Richard W. (1997). “Medieval and Renaissance book production.“. Library Faculty & Staff Publications. Paper 10. https://digitalcommons.usu.edu/lib_pubs/10
#3. James Martin’s Emoji Story- https://blogs.ubc.ca/etec540jamesmartin/2021/10/17/task-6-4-emoji-story/
I chose James’ entry partially because it was depicting one of my favourite movies, but also because of the manner in which he chose to use the arrangement of the emoticons to pictographically represent the scene, which was fascinating to me. I had always used emoticons in primarily informal communications and for the communication of short ideas/meanings or even single words. I had never considered using emoticons in this manner. I wrote my emoji story in a manner that echoed the sequence of traditional written text, is left to right, and listed in the intended sequence for my reader to interpret. James created a spatial organization in which all the elements are viewed at once and the arrangement is what gives the reader meaning, an idea that is echoed by Kress’ (2005) work. I felt that James used the affordances of the visual image more effectively than I did in this task.
Another reason I chose to reflect on this post was it lead me to a realization that I made the assumption that the act of interpretation is different for words than that of emoticons. Kress (2005) notes that images can be used to depict anything and provide meaning through that depiction (pg. 15). I had assumed that this was the case for emoticons; their arrangement and selection are what provided meaning. However, as James points out, these emoticons are all assigned meanings by the creators, thus actually having a finite number of possible elements making emoticons closer in nature to words than image-based depictions. Another element that emoticons share with words is that they are always general and vague, meaning the reader needs to provide the meaning (Krauss, 2005, pg. 15) unless they know how to access the hidden assigned meanings, such as using the read-aloud software of the device, as James did. I noted that emoticons may have a multiplicity of meanings depending on the cultural contexts of the reader, something that James echoes in his response to my comment. He gives the example of a firecracker, which he intended to be an explosion, but our peer interprets it as being representative of Chinese New Year (Martin, 2021). This post really forced me to examine my assumptions about the nature of emoticons and their relationships to images and words.
Kress (2005), Gains and losses: New forms of texts, knowledge, and learning. Computers and Composition, Vol. 2(1), 5-22.
Martin, J. [james martin]. (2021, October 27). Emoji story. [Online forum post]. WordPress. https://blogs.ubc.ca/etec540jamesmartin/2021/10/17/task-6-4-emoji-story/
#4. DeeDee Perrott’s Golden Record Network– https://blogs.ubc.ca/ddperrott/2021/11/04/task-9-golden-record-network/
The reason I selected DeeDee’s posting to reflect on was that I found she shared my experience of trying to decipher the data and struggling to understand the quantitative element without paying equal attention to the qualitative component. As a strong proponent of the usage of algorithms to enhance our daily lives, I had not considered what information may be omitted by them, rather focusing on the benefits, such as bringing information that may be of use or interest to the focus. Seeing the edges and nodes of the Golden Record responses visualized for me the complexity of the network, especially such a large one such as Google, and highlighted how easy it was for some nodes to become entirely disconnected or hidden from all, but the closest scrutiny.
During this module, we also learned that some algorithms take the number of interactions into account to add weight to the degree of the relationships between nodes. This was interesting to me, as I had not previously considered how search engines create the hierarchy of results. As I noted in my comment on DeeDee’s post, I was struck by the potential for the recreation of inequity related to ease of access to information. If weight is determined by the number of interactions, then those with the access to interact with nodes that are of interest to them, or align with personal beliefs, have more influence on the weight and resulting hierarchy used by some search algorithms. This may lead to inequity of access being reproduced in the digital network. Those in positions of privilege determine what information is deemed “more important” due to simply having the privilege to access the online network space. These potential problems with the relationships between algorithms and networks were not something I had considered previously and will continue to be mindful of moving forward.
#5. Chris Howey’s Attention Economy– https://blogs.ubc.ca/chowey/2021/11/08/attention-economy/
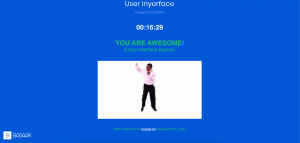
My reasoning for selecting Chris’ post to engage and reflect with was that I felt he had a different experience with the User InyerFace activity than I did. My frustrations came mostly with the fact that I felt this website was needlessly trying to attain my personal information, whereas Chris felt similar frustration with the design elements of the webpage itself. I found it interesting that two people with experience working in the online sphere could have such different experiences on the same web artifact.
I also picked Chris’ post because I really enjoyed the quote that he pulled from the TED talk by Tristan Harris regarding outrage being a good way of getting attention. This caused me to go back and re-watch the video. The main message that I pulled out was the need for accountability in algorithms and the need to maintain ethics/boundaries in the online sphere (Harris, 2017). We learned much about how there are technological advances in search of perfecting the online experience and gathering information about the users, but it remains to be seen how consumers and users can protect themselves and personal information. There may be laws that protect online users, but as we can clearly see in this task, there are deceptive means to an end. This experience reinforced for me the need to teach and learn about responsible digital citizenship, how to evaluate online spaces, and use critical thinking to make informed decisions online. I will strive to continue to practice and teach my students these ideals going forward.
Harris, T. (2017). How a handful of tech companies control billions of minds every day. Retrieved from https://www.ted.com/talks/tristan_harris_the_manipulative_tricks_tech_companies_use_to_capture_your_attention?language=en
#6. Amy Jazienicki’s Algorithms of Predictive Text- https://blogs.ubc.ca/etec540ajazieni/2021/11/21/task-11-algorithms-of-predictive-text/
I chose to reflect on Amy’s post because I thought that the quote she had pulled from McRaney’s podcast correlated well with the article written by O’Neil (2017) regarding the problem with algorithms. O’Neil lists 4 layers of complexities when coming to “bad” algorithms: unintentional problems that reflect cultural biases, neglect, nasty but legal, and those that are intentionally nefarious. Those four categories, combined with the point made by McRaney regarding unintentional sexism of algorithms reinforced a concern that I had identified in the networking task regarding the replication of inequities in the online sphere.
This raises the question for me of what responsibility do agencies that maintain these algorithms, such as a company like Google, have to protect consumers from their own algorithms and the injustices/inequities that may be unintentionally reproduced. Additionally, should it be up to the individual to try to combat these effects online or does there need to be government legislation to maintain those rights? This is a problem that I don’t believe currently has an answer to and needs further consideration as technology evolves at an ever-increasing rate.
McRaney, D. (n.d.). Machine Bias (rebroadcast). In You Are Not so Smart. Retrieved from https://soundcloud.com/youarenotsosmart/140-machine-bias-rebroadcast
O’Neil, C. (2017, July 16). How can we stop algorithms telling lies? The Observer. Retrieved from https://www.theguardian.com/technology/2017/jul/16/how-can-we-stop-algorithms-telling-lies
Reflecting on all 6 Links
A common message that I found myself coming back to throughout the selection of 6 blog posts and the subsequent reflection was how can the rapidly changing text technologies be unintentionally perpetuate societal inequities. I have always been a proponent of the benefit of technology, often amazed at the speed of new developments, as well as how easily I find myself becoming reliant on digital technology for the majority of the methods that I create and consume text. I had never taken the time to reflect on the potential limitations of the way that I interact with text and the need to critically examine my assumptions about texts.
My classmates and I all experienced the various tasks using text in very different ways, which is completely understandable given our different backgrounds, worldviews, cultures, experiences and beliefs. However, I was of the assumption that because we share a similar level of education and interest in technology (assumed because of enrollment in the Masters of Educational Technology program) that we would share more commonalities when engaging with different texts. However, it was a common theme in all the online artifacts that I examined that we had unique experiences. This allowed me to examine some of my own assumptions about when I generate texts for a selected audience, such as my students, and to fully allow open exploration of texts.
In terms of the web authoring tool, all the authors that I looked at used the UBC version of WordPress to present their tasks and reflections. Where there was a difference was in the way that the information was conveyed. Some authors relied heavily on images to represent ideas, others used primarily written text. Less common was other media, such as videos or audio recordings, although I did see these in the posts of other classmates that I did not choose for this activity. Throughout the course, we discussed the benefits of using texts in a way that is not just written, such as Kress (2005) noting that images can be used to depict anything and provide meaning through said depiction (pg. 15), but many classmates still held true to traditional written text. I think that this is representative of how many people interact with the text. Even though how we create text may have changed (such as typing on a computer), we still adhere to traditional rules and formatting since it is comfortable. There is a need for critical thinking and digital literacy regarding how we interact with texts in the new online sphere since traditional methods of thinking don’t always apply to these new mediums.



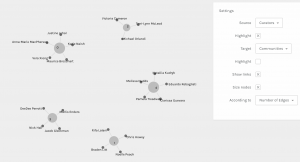 For example, while R. Lalani (2021) used a similar motivation to my own, trying “to have some measure of geographic and racial diversity represented” for part of the curation. It quantitatively and qualitatively makes logical sense for us to share a community. In contrast, Noelle (2021) tried to “use ‘math’ to match the songs from the record to Voyager 1 and 2’s most important events while they were within our solar system”. We did not share nearly the same motivations, yet both the quantitative value of the number of edges and nodes groups us together.
For example, while R. Lalani (2021) used a similar motivation to my own, trying “to have some measure of geographic and racial diversity represented” for part of the curation. It quantitatively and qualitatively makes logical sense for us to share a community. In contrast, Noelle (2021) tried to “use ‘math’ to match the songs from the record to Voyager 1 and 2’s most important events while they were within our solar system”. We did not share nearly the same motivations, yet both the quantitative value of the number of edges and nodes groups us together.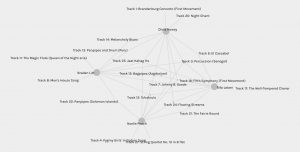 If weight is provided by interactions in many online algorithms, nodes that are not interacted with frequently are placed further down the hierarchy of search results. That means that the more privileged populations who can easily have Internet access see their priorities and preferences reflected in the online space, whereas those who are already at a disadvantage may have potentially beneficial nodes pushed from ‘view’ with the massive size of the network. This null data can potentially serve to reproduce and perpetuate inequalities that already exist.
If weight is provided by interactions in many online algorithms, nodes that are not interacted with frequently are placed further down the hierarchy of search results. That means that the more privileged populations who can easily have Internet access see their priorities and preferences reflected in the online space, whereas those who are already at a disadvantage may have potentially beneficial nodes pushed from ‘view’ with the massive size of the network. This null data can potentially serve to reproduce and perpetuate inequalities that already exist.
