This week I had the opportunity to explore Craiyon. I have used other text-to-image platforms such as Adobe Firefly and Open Art AI to create images before and I was curious to experience this one. It was my first time using Craiyon. I really liked that Craiyon allows users to use the tool without providing any form of personally identifiable information or account creation because often data and privacy concerns are considered when using generative AI tools. While I can see that this platform can be intuitive and easy for individuals to use, particular things stood out to me that are worth noting which I will discuss in more detail below. I went on a hike with my friends recently, so I was inspired to use that as the initial prompt.

Was the result relatively accurate in your estimation?
The results were somewhat accurate, but not exactly what I had envisioned in my mind. When given the prompt “friends on a hike”, the platform was able to generate a collection of photos quickly. This AI-powered image generation tool can create unique and complex images from textual input, but it lacks the sophistication to capture human physical characteristics/attributes accurately (i.e., faces, fingers, body positions, etc.).

Were those images what you had in mind when you gave the AI the prompts? What differed?
Craiyon did a great job at generating highly versatile and realistic backgrounds for the hiking scenes such as the greenery, abundance of trees, and trails. However, the tool seemed to have difficulty capturing and representing facial and body features. When looking closely at some of the generated photos, the faces of the individuals are morphed. The placement of the arms and legs is off (i.e., arms are placed in odd positions, fingers and hands are missing, legs are in weird positions, etc.). When I gave the AI the prompt, I expected to have realistic and true representations of individuals on a hike. In this case, the AI was able to satisfy my expectations of the hiking part of the prompt, but not the “friends” part. This is significant because it demonstrates that there is still room to improve the sophistication of this AI tool. Moreover, this tool provided me with other suggestions for more detailed prompts such as “group of lively friends trekking up a scenic mountain trail” and “bonding experience of friends laughing and chatting on a scenic hiking trail”. The generated photos seemed to have more details and variations of scenic trails, but the morphed facial features and body parts of the individuals remained the same.
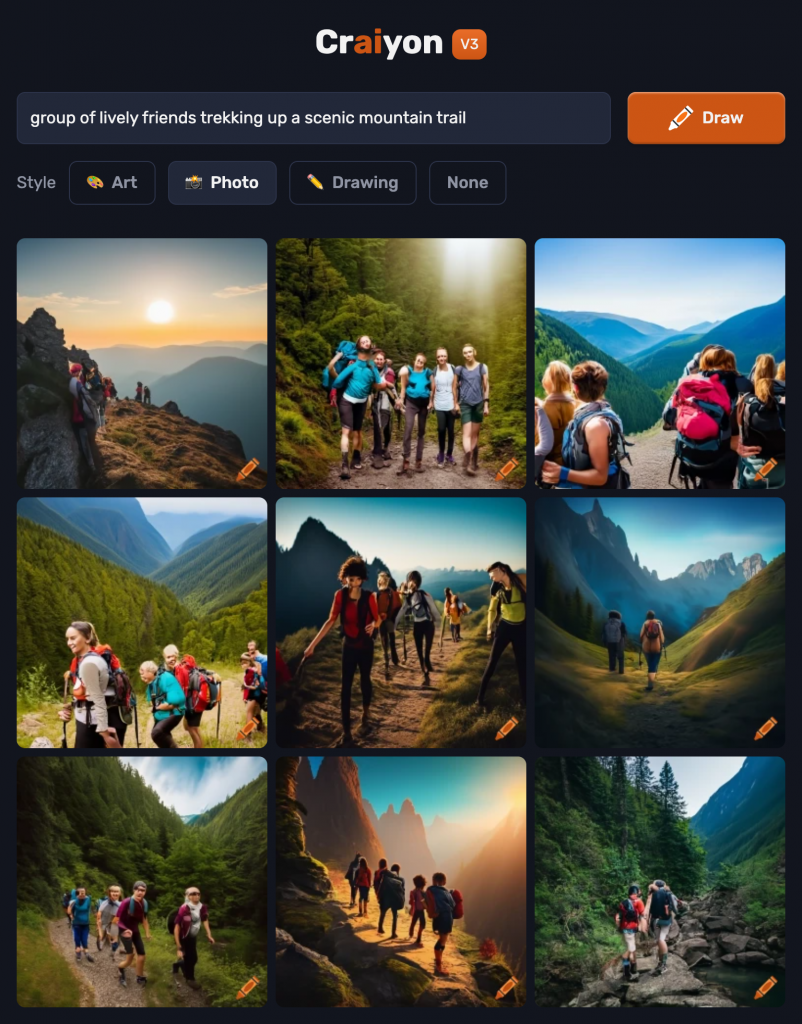
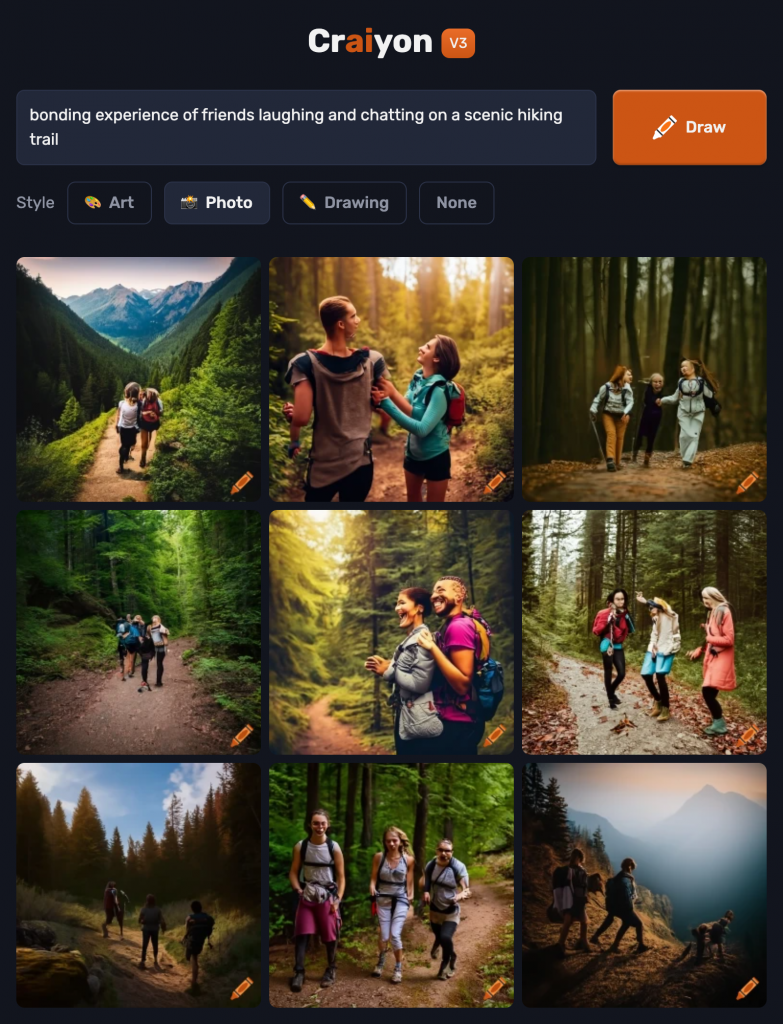
What can you infer about the model or the training data based on the results?
This exploration showed me that there is still work to be done on AI-generated image generators. It emphasizes that technology still has its flaws. I found that there were limitations when it came to the “norm” of what certain features should look like. In addition, when looking closely at the photos, I noticed a limited representation of cultures and disabilities. Most of the generated individuals or the “friends” are Caucasian. In connection with the EDIDA framework, which emphasizes Equity, Diversity, Inclusion, and Decolonization, I recognized the limitations inherent in AI-generated representations. These limitations underscore broader societal challenges regarding representation and inclusivity in technology. As I move forward in my learning journey of generative AI tools, this is something I would like to see change as we move forward in technological development and advancement.
References
Heilweil, R. (2022, December 7). AI is finally good at stuff, and that’s a problem. Vox. https://www.vox.com/recode/2022/12/7/23498694/ai-artificial-intelligence-chat-gpt-openai
Storied. (2021, May 5). From Alan Turing to GPT-3: The Evolution of Computer Speech | OtherWords [Video]. YouTube. https://www.youtube.com/watch?v=d2UccTPnl4w
UBC Education. (2022, January 17). Equity, diversity, inclusion, and decolonization [Video]. YouTube. https://www.youtube.com/watch?v=QY4gXxdmLgM