Algorithms of Predictive Text
This week’s task to use the predictive text feature of our smartphones to generate a microblog about a prompt resulted in the following:
This is not my idea of a good job offer but it’s ok. The only way I can find a new one is the best thing for me. LOL I’m so excited to have a new phone. I think it’s ok if you don’t want me to go back to work. The only reason why I don’t want to go back to work is because it’s not too much fun for me. I have to get tested for this one day and then I’m gonna try to get it done before the end of the week. LOL I hope you are doing ok today. I think it’s too bad I don’t know how much it will work out for me. The first time we had the same experience with that one day I have been accepted to a PhD program at the university of Toronto and the other day that we were doing this is the best way to get it done. The following day I was like oh wow lol ???? I didn’t know if it would be a nice day to go out there to see if I could go to the park for a while. The first two seasons of this year were also in May by two and three, the only time in May last year of that period was a little disappointing. I think I will be able to make a decision to go back to work tomorrow. I don’t think it’s so weird to say I am so sleepy ????. The first time in May was a little bit more fun than the last time. I think it’s the best thing to do. The only way to get a little better is to go back to sleep.
The microblog above best reflects simple everyday language used in casual text messaging conversation, rather than more sophisticated language used in novels or academic texts, and even more simplistic than the less sophisticated language used in magazines or blogs. In this way predictive text is reflective of the style and voice of my text messaging. I begrudgingly admit to overusing LOL, which came up as an option every time I typed a period. Every time I typed good the word lord was included in the next option. I do say good lord a LOT. There are other words that came up as predictive text options that I attribute to the following:
- when I text my mom goodnight I often use the word sleepy
- when I discuss work with a good friend who was furloughed last year
- I’ve been texting friends recently to share the amazing news that I have been accepted to a PhD program at the University of Toronto
As much as I think the predictive text has learned from me, I don’t think it has a lot of range or sophistication, and it clearly hasn’t picked up on all the cursing I do – it usually takes me several attempts to type duck every time I want to use it – and I’m shocked an option for y’all never came up with other pronoun options. I was annoyed the same few beginning sentence options repeated themselves over and over again. I could only begin a sentence with I followed by a limited verb set have, think or don’t or The followed by first, only, or following.
Algorithms: Harmless or nefarious or somewhere in between?
On the surface, useful everyday technologies like Siri, spam filters, and predictive text that use neural networks and language in corpuses such as the Enron emails’ unfettered conversations and the past 50 years of texts used in Word2Vec seem fairly harmless (Herman, 2019; McRaney, 2018). But a few ideas in this week’s material are cause for alarm: Cathy O’Neil shares with us that algorithms learn from the past to shape the future and that their output is as biased as the data input that feeds them, and Alistair Croll shares that “algorithms shit where they eat” causing predictions to become reality and that “output is tied to input in unexpected and not obvious ways” (Mars, 2017; )
Last February I read about OpenAI’s text generation project that was supposed to be open but became shrouded in secrecy, because the company’s mission to create open source software was thwarted by ethical concerns about the software being misused in harmful or destructive ways. I went down the rabbit hole and found a similar text generation website called Talk to Transformer that uses Inferkit‘s neural networks to generate text and played around with it. Though the technology was impressive, there’s something unnatural and a bit bizarre about the following screenshots from last February. FYI, the first example is NSFW.



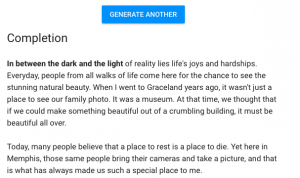
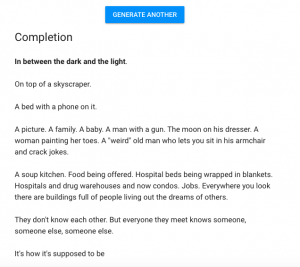



The output seems to be generated randomly, and in the above examples, it would seem the corpus might come from fiction texts, and the NSFW example seems to be pulled from the genre of erotic fiction.
But what if the software allowed for the user to input other parameters that would tighten up the corpus and shape or meaning of its generated output? What if I could generate text to pass off as my own academic work? I tried it again for the purpose of demonstrating how text generation can be used to autocomplete some of the ideas in this blog post, and I used it with this prompt:
On the surface, the creation of useful everyday technologies like Siri, spam filters, and predictive text that use neural networks and language in corpuses such as the Enron emails’ unfettered conversations and the past 50 years of texts used in Word2Vec’s corpus seems fairly harmless.
And Talk to Transformer came up with this:
On the surface, the creation of useful everyday technologies like Siri, spam filters, and predictive text that use neural networks and language in corpuses such as the Enron emails’ unfettered conversations and the past 50 years of texts used in Word2Vec’s corpus seems fairly harmless. And indeed, many are hailing Word2Vec as a powerful breakthrough for understanding the shared nature of human communication. However, the very real possibility of issues relating to fairness and trust has important ramifications.
The Sroufe Lab at Stanford University and the BCG Digital Finance Lab have since used Word2Vec to answer the very basic question: how do you build trust between bots? What is the algorithm that should an average person trust?
Fairly convincing? How about this one?
On the surface, the creation of useful everyday technologies like Siri, spam filters, and predictive text that use neural networks and language in corpuses such as the Enron emails’ unfettered conversations and the past 50 years of texts used in Word2Vec’s corpus seems fairly harmless. But dig a little deeper and you’ll find a more sinister subtext—a vast, never-ending collection of the human past being explored by a criminal mind and monetized for the benefit of an oppressive, surveillance state. It’s about using machines to perform forensic analysis and identity theft, to expose people’s hidden (often mentally ill) activities and information that can be used to produce a false report and “gotcha” moment.
What if I could upload the entire corpus of my academic writing, so it could learn my voice? Then what if I could generate text pulled from relevant articles and journals based on a research project of my choosing? We know that a group of students from MIT built a text generator and used it to generate scientific articles that passed the peer-review process and were published in journals. The misuse of this technology for academic dishonesty is just one example of a potential harmful use of algorithmic technology. When algorithms are already so widespread and poorly understood, their ability to “make it unfair for individuals but sort of categorically unfair for an enormous population as it (sic) gets scaled up” is a bit frightening (Mars, 2017). Much needs to be done to create awareness for users of everyday technologies that use algorithms and to design ethical frameworks for the creation and implementation of algorithms.
Herman, C. (Host). (2019, June 5). You’ve Got Enron Mail! [Audio podcast]. Brought to You By… https://art19.com/shows/household-name/episodes/354d6bd0-d3f6-4536-80b5-c659fc47399f
Mars, R. (Host). (2017, September 5.) The Age of the Algorithm [Audio podcast]. 99 Percent Invisible. https://99percentinvisible.org/episode/the-age-of-the-algorithm/
McRaney, D. (Host). (2018, November 21). Machine Bias (rebroadcast) [Audio podcast]. You Are Not So Smart. https://youarenotsosmart.com/2018/11/21/yanss-140-how-we-uploaded-our-biases-into-our-machines-and-what-we-can-do-about-it/
One reply on “Task 11”
Thanks for sharing those text tools – I’ve never played around with any of those and I’m impressed at how realistic their outputs are. As technologies like this get stronger, I’m sure they’ll be countered by different AI that are used in assessing assignments and job applications, AI that are designed to weed out AI-generated content. In addition, our hiring and assessment processes will likely have to veer more towards project-based challenges and multiple rounds of interviews to help human assessors weed out AI content as well. It seems like multi-round and project-based job interview processes are already becoming the norm anyway.