Overview:
Unsupervised classification is where the algorithms try to sort the image based purely on statistics with no ground truth input. Classes are usually called clusters and the computer clusters spectrally similar pixels together. There are two basic methods of clustering:
- searching in spectral space for clusters and then assigning the pixels to the classes/clusters
- searching in pixel space (i.e examining each pixel and deciding if it is in a cluster or is in fact a new cluster)
Objectives:
- List the steps in unsupervised image classification
- Discuss unsupervised cluster collection methods
- Use PCI unsupervised classification algorithms
- Perform unsupervised image classification
Summary:
PCI Geomatica provides several methods for creating clusters. The two methods that PCI uses are:
K-Means Classifier: This algorithm samples a subset of the image during cluster mean calculation. The size of the sample depends upon the amount of image data. Each pixel of image data is assigned to the cluster whose mean vector is closest to the pixel vector. A new set of class mean vectors is then calculated from the results of the previous classification and the pixels are reassigned to the new cluster vectors. The procedure continues until there is no significant change in pixel assignment from one iteration to the next or until the number of iterations has reached the maximum number specified by the user. Once the iterations are complete, the cluster mean vectors are used to classify the entire image.
ISODATA Classifier: ISO DATA algorithm statistically examines each cluster and applies the following three criteria:
1. Clusters having too large a standard deviation are split to form two smaller clusters.
2. Clusters that are statistically too close to one another in the multi-dimensional measurement space are merged into a single cluster.
3. Clusters with too few pixel members are discarded. ISODATA is useful when you are not sure about the number of clusters to use.
Unsupervised vs Supervised:
Unsupervised classification is different in two ways from supervised classification. Firstly there are no training samples, rather than the software tries to find the classes or clusters automatically in the image. Secondly, the resulting clusters must be labeled (i.e this cluster is hardwoods). This can be difficult as some clusters the computer selects may be meaningless measures that represent mixed classes of land cover materials.
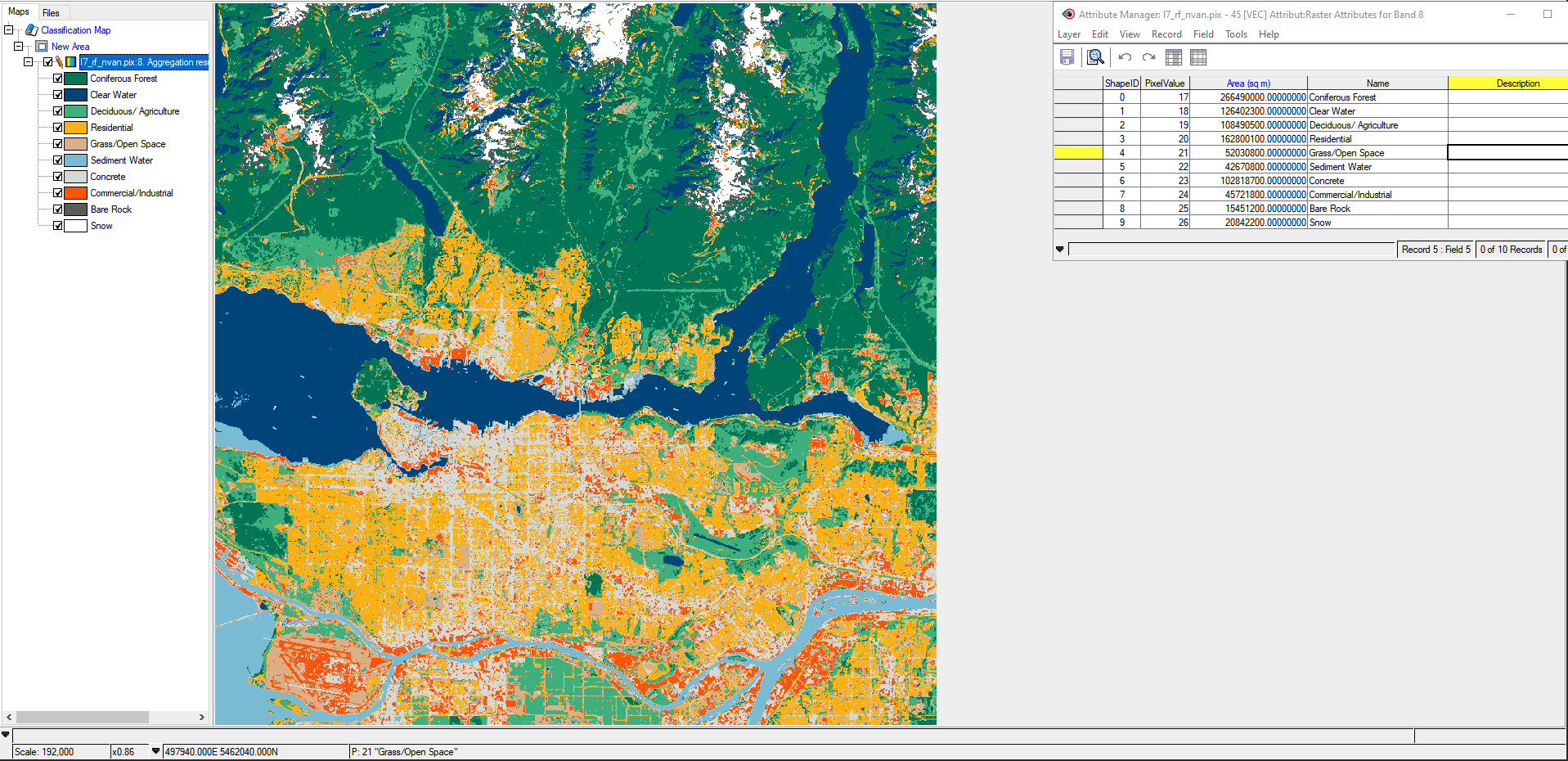
ISODATA Unsupervised Classification of North Vancouver. Divided into 10 classes.
The purpose of this lab was to create a land cover image with a table indicating area (ha) for each land cover in the North Vancouver area (image above). All three PCI unsupervised classification methods were used (K-Means, Fuzzy K, and ISODATA). Looking at the results, I believed that the ISODATA sorted the land covers out the best. PCI Geomatica found 16 clusters which in turn were turned into 10 classes.