I created an infographic about Instagram as a multimodal literacy tool for participatory culture and connection. I used Genially, which allows for additional interactivity. Please click on the moving icons below to read more about that particular section. Unfortunately Genially took away the ability to download projects as PDF’s; I’m hoping the embedded infographic below will suffice! To expand the infographic, scroll to the bottom of the embedded window and click the full-screen icon (two opposing arrows), found in the lower right corner. Here is the direct link to the infographic for increased readability: https://view.genially.com/668c1eba4904770014a06a25/interactive-content-instagram-etec-540
Task 12 – Speculative Futures
Here is the prompt from The Thing from the Future that I selected:
Describe or narrate a scenario about an artwork found a century into a future in which society as we know it has come apart. Your description should address issues related to identity and elicit feelings of dread.
I decided to depict my scenario in 2 different ways. The first is using a free text to speech tool called Natural Readers. In my search for text to speech tools, I wanted to find one that sounded more natural than many of the voices included in free tools. Because this tool only allows for a few minutes of speech to text per day and does not allow for downloads, I ended up using my iPhone Voice Recoding app to record my text in two different parts. I then stitched them together and created the following audio file.
I also wanted to experiment with an AI video creation tool to create visuals for my text, however many of these tools are not yet released to the public (such as Sora), or they’re not currently free. I found a tool called VEED that would take my transcript and transform it into a video. However VEED has a time limitation, so it shortened my story. I noticed that the tool seems to be geared toward ‘Instagram-esque’ reel videos, including caption text with emojis superimposed on top of imagery. I found the emojis and the imagery that VEED selected to be interesting. It appeared to select emoji’s from key words that I used in my script, but they weren’t necessarily the best choices (in my opinion). For instance, when ‘work’ is mentioned, VEED selected a safety vest as the most appropriate emoji– not the best emoji for the context of the script. Additionally, the background imagery the tool selected was interesting, but they were also not particularly apt to the context of the script that I fed the tool.
I also could not download the video from VEED, so I used a screen recorder tool to capture the video during playback. I couldn’t crop the screen after downloading the video, so please don’t mind the multiplicity of tabs I have open. 😀
Here is the text version of my scenario, for those who prefer reading: Task 12 – Speculative Futures Text
Task 9 – Network Assignment using Golden Record Data
I decided to use a screen capture video with audio for this task. Check out my analysis and reflection below:
Task 10 – Attention Economy
What a frustrating and anxiety-inducing experience!
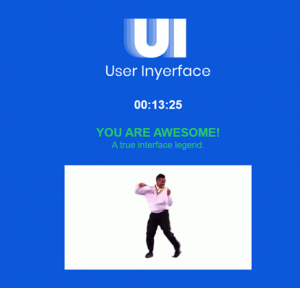
Upon starting the User Inyerface game, several annoying things immediately misdirect my attention. There is reference to filling out a form as quickly as possible, while there is no form on the page. The button looks clickable, but sends mixed messaging by having the word “no” printed on it. The text at the bottom of the page appears to have no hyperlink, even though it has underlined text as well as text with a hyperlink-esque colour change included. Welp! Quickly discovered that the NO button isn’t functional, and ended up spending quite a bit of time finding the hyperlink hidden within the capitalized word “HERE”. This directly ignores all of the ‘rules’ about the internet we’ve come to assume are commonplace across websites.
Immediately on the next page, flagged with a countdown and a red banner, I am struck with a wave of anxiety. I am concerned with being on a page that is using cookies, and I cannot get out of the scenario to adjust that! This is a great example of what Harris (2017) mentions in his Ted Talk about programming interruptions in attention in order to manipulate human emotions and behavior. I definitely have a leaning toward anxiety in generally, but definitely during any kind of countdown ( as an aside, I think this is pretty common, especially in scenarios related to timed testing). I’m sure it has roots back to those Mad Minutes that were so common in math classes during my generation’s upbringing. Both my attention and my emotions were meddled with here. This underscores the point that Dr. Tufekci (2017) touched on– that large corporations that are profiting off our data will use individual weaknesses and vulnerabilities in order to make us feel a certain way. Additionally, she mentioned that these corporations can even use data to predict when people who have bipolar disorder are going to enter a manic episode, and subsequently lean into the vulnerabilities of that in order to profit. Sickening, but not surprising.
Another alarming feature of the site that stuck with me is the profile image section. I had to upload an image from my computer to continue, but when I clicked the misplaced “download” button to upload the image, the website actually downloaded its own image to my computer! This is precisely the scenario that I have to warn my aging parents about all the time: do not click any download links from unfamiliar websites, because this is how you can very simply download a virus. The nefarious part about this part of the site is that it was labelled incorrectly, intentionally misdirecting users into its plan.
The last notably annoying feature that I’ll discuss is the image selection portion, in order to prove that you’re a human. This portion of the game asked for the user to identify all the glasses in the photos; meanwhile the pictures displayed varied between eye-glasses, panes of glass, and drinking glasses. There is no way for a user to know which homonym the site is asking for, leaving them confused and requiring them to spend time figuring it out through trial and error. Bringnull (2022) mentions that these kinds of trick questions or tasks are intended to confuse users into deception.
This whole experience drives home the point that we must be aware of the ways websites, algorithms, and companies manipulate our experiences online to get us to do what they want: spend more time on sites, make more of our data available, and spend more money, among other things. Our attention and emotions are easily manipulated if we are not mindful of the tactics of dark patterns.
Despite the frustrating and alarming experience, I did end up making it to the end. Woohoo!
Brignull, H. (2011). Dark patterns: Deception vs. honesty in UI design.. A List Apart, 338.
Tufekci, Z. (2017). We’re building a dystopia just to make people click on ads. [Video]. TED.
Task 8 – Golden Record Curation
This was a very engaging activity to think about… and very challenging to try to come up with some kind of criteria to cull down the list of 27 songs from the Golden Record to only 10! I decided to curate my selections based on both Diversity of Representation (continental origin) as well as Variety of Sounds/Genres. The Golden Record was curated to feature cultural diversity already, but several of the selections feature classical music of European origin. I decided to only select one of these songs, and ensure the rest of my selections represented more geographical variety. Additionally, I chose songs that had the most diversity in instrumental/vocal sounds. It was mentioned in the Voyager Golden Record podcast (2019) that any kind of alien intelligence may not have the same capacity to hear sound frequencies in the same way humans can, so in selecting a variety of instrumental sounds, we maximize the potential that some of these sounds could be identified or mean something to other life forms.
Here is my curated list:
- Wedding song – (Peru, South America)
- Tchenhoukoumen, percussion (Senegal, Africa)
- Kinds of Flowers (Indonesia, Asia)
- Flowing Streams (China, Asia)
- El Cascabel (Mexico, North America)
- Ugam – Azerbaijan bagpipes (Azerbaijan, Europe/Asia)
- Jaat Kahan Ho (India, Asia)
- Navajo Night Chant (America, North America)
- Morning Star and Devil Bird (Australia/Oceania)
- Bach – WTK 2, no 1, Glenn Gould (Germany, Europe)
Reference:
Taylor, D. (Host). (2019, April). Voyager golden record. [Audio podcast episode]. In Twenty thousand hertz. Defacto Sound.
Task 7 – Mode Bending
Listen to my “What’s in my bag – the riddle edition” recording above!
When redesigning this task, I immediately thought about how mode-bending lends well to upholding Universal Design for Learning principles: Multiple Modes of Expression, Representation, and Meaning. For all learners, and not just those that require accommodations, there’s a great value in allowing learners to contextualize and redesign their learning into a product that’s meaningful to them. The New London Group (1996) states that the “redesigned” is unique product of human agency that is concurrently influenced by cultural and historical patterns of meaning (p. 76). This is definitely apparent in how I chose to go about redesigning Task 1 using a new mode. I’ve always enjoyed riddles as far back as I can remember. As soon as I began reading and was able to check books out from the library, I would often gravitate toward the joke and riddle books. A contributing factor to this could have been my 3rd grade teacher using riddles often in the classroom, to engage and motivate students in different ways. I can see how this teacher took what the New London Group refers to as overt instruction, and linguistically redesigned the mode of engagement to build on prior knowledge, scaffolding toward new knowledge acquisition.
I decided to redesign my original task auditorily, utilizing both riddles (linguistic design) and sound effects (auditory design) to engage listeners in a different way. I think the riddles inject a personality and ‘voice’ into the task that wasn’t available before. They also paint imagery into the listener’s minds, changing their experience with the task.
Benefits and Challenges
Changing the mode of a production can give learners with strength in multiple intelligences (Gardner) additional ways to integrate learning in a more personal way. For example, transforming a vocabulary list into a recognizable song could help those with musical intelligence to integrate concepts in a way that’s more meaningful to them. A potential challenge of mode-bending might be that references may not be culturally situated or accessible for learners from different backgrounds, making it difficult to make meaning for some. For instance, in cultures where vehicles are not commonplace, or a person has auditory impairments, my riddle that references car keys would not be received in a way that meets the listener where they’re at. This underscores the value of designing for a variety of modes of meaning making, or Universal Design for Learning.
As a note for this task, I did employ a bit of help from ChatGPT to help me with a few of the riddles. I also used royalty-free and open-sourced sound effects from PixaBay.
OpenAI. (2023). ChatGPT (June 18 version) [Large language model]. https://chat.openai.com/chat
Pixabay (n.d.). Pixabay – Royalty Free Sound Effects. Retrieved June 18, 2024 from https://pixabay.com/sound-effects
The New London Group. (1996). A pedagogy of multiliteracies: Designing social futures. Harvard Educational Review 66(1), 60-92.
Linking Assignment
Task 1 What’s in My Bag
Lucy’s Submission
Lucy included many of the same type of items in her bag as I did. We have snacks, a water bottle, an actual backpack, keys, wallet, and a notebook in common. Some of the differences include self-care items like medicine, ointments, handcreams, sunscreen from her bag, and mine includes more elements related to the activities that I take part in such as a volunteer badge, a softball, and a watercolour set. Regardless, we both noted that these items speak to our personalities, and the way we are perceived and understood by others in the world around us. Lucy seems much more prepared for environmental factors that may change around her, ensuring that she has what she needs to be comfortable. I’m usually that person who would be asking her for a Tylenol/Advil! Thank you Lucy for being that person! 😀 I am usually the person who only takes what’s essential for the activity that I’ll be engaging in—somewhat more of a minimalist. As I mentioned in my post, I took a photo of many items that make it into my bag at some point in time, but rarely would all of these items be in my bag at the same time. Lucy made a comment about the contents of her bag giving other people an impression of who she is on a particular level, but these items cannot fully demonstrate who she is personally or professionally. I certainly agree with this statement, and feel a similar sentiment. Although the technologies and texts that we carry with us can demonstrate some of our preferences, they cannot paint a full picture of who we are as people.
Task 3 Voice to Text
Carlo’s submission
Carlo’s speech-to-text task experience mirrored mine in the way that punctuation, run-on sentences, and incorrectly translated words were apparent in his unscripted anecdote. I also had words missing in my script, likely due to not pronouncing them clearly enough. Carlo did something a bit different with his script though; he went through and edited the output of his script to make it make more sense. He took a story that was intended to be somewhat informal, and turned it into something that followed the rules of punctuation and grammar. He noted that if he had scripted the story, it would have eliminated a lot of the errors that Speechnotes made in his dictation. However, the story potentially wouldn’t have included the same personality and ‘humanity’ if it was scripted and written out perfectly.
I saw many of these same parallels within my speech-to-text story. Although I used the iPhone speech-to-text functionality (as opposed to Speechnotes used by Carlo), we had similar observations about the lack of these technologies to capture tone, cadence, emotion, and other dramatic spoken effects. This made me think about the choice to use free tools rather than paid voice to text technologies, and whether or not there will be a way for speech to text technologies to capture tone, emotion, and dramatic effect. I mentioned to Carlo in a comment that there are new tools being developed that are starting to address this need:
“…This made me think of an AI tool I saw recently that does capture expression, albeit in a slightly different modality. Signapse (https://www.signapse.ai/) is an AI generated sign language interpretation tool that utilizes an emotive human-like AI. Facial expressions are super important in sign language, and this tool seems to pick up on those expressive cues in its translation. I can definitely see speech-to-text technologies getting to the point where they’re similarly identifying and conveying emotions in their transcription.”
Task 4 Manual Manuscripts
Brie’s submission
The first thing I noticed about Brie’s submission was that they also composed their manual manuscript on less traditional paper. Instead, they used “dot grid journal” paper, which lends itself to creative processes like bullet journaling. Brie noted that their hand-writing doesn’t go through the same “scattered, iterative looping” process that their typing generally does. Personally, I find composing through typing to be a more ‘formal’ method of writing. I tend to lean into the informality of hand-writing, allowing it to be scattered and iterative and as a means to recontextualize thoughts in multiple non-linear expressions, as a way to ‘work things out’. For me, hand-writing leans less on a clear final product, and is more about the process of expressing without needing to accomplish something specific at the end. I really appreciate how Brie made this connection, as it helped me to recognize this about my own writing process. Brie also mentions that word processors make suggestions for brevity and conciseness, and this impacts the final product of a piece of writing. This is an excellent point! When we write in a technologically mediated way, we are prompted to modify our writing in the moment by a force outside of our own ‘voice’. When writing a letter in a personal journal, perhaps there’s less of a desire to ‘correct’ our voice.
Brie’s site architecture
Brie’s assignments are hosted on UBC Blogs, and they selected a theme that provides a clean and spacious interface. The simplified navigation bar appears on each page, and allows viewers to navigate between 5 main sections: Home, Activity, Tasks, Linking Assignment and Final Project. This design is different than mine in that I’ve linked each Task in its own category, and those categories appear on the main navigation bar. I decided to do this because, as this course is reliant on the cohort reviewing each other’s tasks in a quick and easy way, it made sense to give each task its own category/link. However, this does clutter up the page a bit. I like that Brie’s Tasks are all included on a page of their own, in their own category. There is one challenge to this architecture though; it does require readers to scroll from the newer tasks at the top to the older ones at the bottom, which is a less direct way to ‘page’ directly to the task they’re looking for. However, each of Brie’s tasks has their own URL, and the CTRL + F function could be used to find specific task titles.
I also notice that Brie chose a theme that allowed for their text to take up more ‘real-estate’ in the middle of the page. I struggled at the beginning of this course, deciding between themes. I wanted to choose something that was clean, easy to follow, and provided enough space for the reader to be able to easily focus on the entries. I like Brie’s theme selection better for this, as I find the font choice in my theme to be somewhat small. I find that WordPress takes some ‘getting used to’, and although one can make changes to HTML code in posts, the themes seem a bit more complex to create and customize (at least for an unseasoned WordPress user). Brie seems like they’ve worked with WordPress before, and they’ve made their site intuitive to navigate.
Task 6: Emoji Story
April Huang’s Submission
The first thing I noticed about April’s Emoji story is that she used about 1/3rd of the emoji’s I did. She mentioned that she chose to use an episode from a TV show she had watched very recently, while it was fresh in her mind. This is a bit different than my approach ( I watched a whole movie and transposed the plot into emoji’s during that process). I wonder if the fact that she used a TV show for her emoji story (which is shorter) and the fact that she relied on her memories of the plot contributed to a more succinct interpretation.
One thing that April noted is that she first wrote a few sentences that summarized the key moments in the show, and then selected emoji’s that best captured those ideas. This approach helped her to be more efficient with her emoji’s. It also seems that her show only appeared to have three main characters, some of which were repeated within her story. I also selected particular emoji’s to represent characters, however, the movie I selected had many more characters. Each part of the plot of my movie centered around particular characters. This could have contributed to why I felt the need spell out to whom things were happening in my movie with those representative emoji’s.
April also mentions very aptly that her movie plot seems straightforward to her due to her interpretation of the emoji’s she used. When looking at her story, I see the two-mask emoji as representative of drama, because I used it as such in my story. Although I’m not sure which TV show she is describing, I don’t think she is using that emoji with the same intention/meaning. I suspect the first line of her emoji story is the title of the TV show, but I’m not totally sure of that—it could be the title of the episode of the TV show. This is a bit different for a movie, as it has a concrete title. I did end up addressing the title after transposing the whole plot, which was needed for my process. For April’s process, this wasn’t as necessary. April’s observation that digital technology blurs the distinction between author and reader, empowering readers to interpret and engage with the content as creators is spot on here. Overall, we had very different processes and results, but we both depended on our own interpretation and the arrangement of the emojis sequentially to impart our storyline.
Task 8 Golden Record Curation
Steve Acree’s Submission
Steven’s selection criteria was similar to mine for this task. We both sought to include tracks that featured a diversity in continental geographic location, as well as stylistic or instrumental diversity. However, he included an additional criterion: how these pieces represent musical evolution over time. This was an interesting addition that ultimately made our curated lists differ. Additionally, he chose to select songs that featured the human voice more often, whereas I focused on choosing songs that featured both voice and diversity in instruments and tones. It is interesting that we only had 4 songs in common, despite some mutual categorization choices. Our interpretation of the criteria is what ended up making the difference, which is to be expected based on our differences in life experience and preferences.
“Hi Steve,
It looks like we both used similar criteria to curate our selections. I also looked at geographic regions/continents as well as stylistic diversity. You mentioned in your reflection that most of the pieces you selected featured the vocals prominently, such as Wedding Song. I also chose many pieces that featured vocals, but I also wanted to ensure that the instrument choices were as diverse as possible. So, I opted to select songs that featured as many unique instruments as possible. The criterion you chose regarding showcasing musical evolution is interesting, and one that I hadn’t considered! Choosing pieces over a timeline can certainly showcase the changes in the musical artform over time. The Golden Record digital recordings that are relatively ‘recent’ in the grand scheme of humans making music (some of the earliest instruments discovered date back to 35,000 years ago). This makes me think more about the Youtube video by Dr. Smith Rumsey (Brown University, 2017) regarding creating digital records for preservation for future generations and research. The records we have regarding music predating recording technologies are nil—we cannot refer to them. But they have made a massive impact on how we relate to music now, culturally, and amongst the human race as a whole. If we could somehow go back in time and get recordings of these very early beginnings of music, do you think they would be important to include by the timeline criterion you’ve suggested? It’s funny to think that, by the time any life form ostensibly finds this Golden Record, music will likely have changed to something beyond our current comprehension. Or, more likely, humans will have ceased to exist completely, but record of our existence will still be ‘out there’!
Thanks for your post!
-Lachelle”
Brown University. (2017, July 11). Abby Smith Rumsey: “Digital memory: What can we afford to lose?”. [Video]. YouTube
Task 12 – Speculative Futures
Steph’s Submission
I really appreciated Steph’s take on assignment 12. It was different than my submission in that it’s less of a narrative story, and more about describing her scenario. We both addressed the larger potential for mental health issues in the future, as well as isolation and disconnection. It’s interesting how looking to the future, it seems to be common to extrapolate on and magnify the current mental health crisis. Despite major technological and medical advancements, it’s difficult to imagine a future where mental health issues will lessen. I could definitely see a scenario like Steph described transpiring. A product like SereniTea could be positively and persuasively marketed, normalized, and become as widely accepted as drinking water or coffee. Perhaps it could even become ‘rewarded’, with SereniTea points accumulating for each purchase or consumption! Stephanie’s scenario really makes me consider whether it’s possible for society as we know it to address the root causes of anxiety, depression, and other mental health issues, rather than medicating and aiming for a calm and orderly status quo. Is this even possible, given the profitability of mental health issues in our capitalistic culture? I hang on to hope that it’s possible. Thanks for this thought experiment, Steph!
Task 6 – Emoji Story


When doing this task, I found it challenging to find a way to symbolize the different characters with the limited “emoji palette” on the iPhone. I ended up watching the film while doing this assignment, trying my best to summarize nuances of the plot as it went along. I think I likely added too many specific plot details that others may not remember if they had watched this movie in the past, and were simply recalling the plot. Additionally, there were elements to the plot that didn’t have a great symbolic emoji (such as a waiter, which is surprising!).
I had to make some compromises to link together emojis to try to communicate the message, and looking back on it now, I can see how the storyline could be misinterpreted by readers. Although I primarily tried to use symbols to communicate the plot, I had to rely on specific emoji’s to represent the actions and emotions of each character: the blonde haired person emoji represents one character, the brown haired person emoji representing another character, etc. Although my intent was to describe the storyline between the characters, a reader of my emoji story may or may not interpret it in the same way. The act of transposing my interpretation of a film’s plot into images, or “reverse-ekphrasis”, as Bolter (2001) called it, leaves quite a bit of room for misinterpretation– in the way I’ve interpreted the plot into words in my mind, selected from a limited palette of emoji’s, and even further as a reader translates these emojis back into thoughts and words in their own minds. Bolter (2001) states “Although the writer and reader may use words to describe and interpret [a] pictorial message, two readers could explain the same message in different words, and speakers of different languages could share the same system of picture writing”, which explains this complexity well.
When choosing a film to use for this task, I didn’t select it based on how easy it would be to visualize. I selected a film that I have watched a few times and really enjoyed as a ‘cult classic’ in my formative years. It’s not a super popular film (although it is currently on Netflix). I think because this film follows a somewhat plausible human storyline, and doesn’t include really specific notable character roles (like super hero/action films generally do), it was much more difficult to transpose into emoji’s. After transposing the film into emoji’s, I then went back and created the title. Only after choosing the specific character emoji’s in the plot could I select the emoji’s for the film’s title. It will make sense if you can guess the film, and you have watched it!
For those that are curious which film this is, I’ve included the title of the film at the end of this blog post in white font. Use your cursor to highlight the space below to see the film’s title.
Frances Ha
Bolter, J. D. (2001). Writing space: Computers, hypertext, and the remediation of print (2nd ed). Lawrence Erlbaum Associates.
Task 4 – Manual Script
Here’s a photo of my manual script, and a few photos of the spaces I’ve referred to in the passage:




Manual Script Reflection:
This assignment was natural for me; I often write in my journal by hand. It’s been something in my life that’s become cathartic. I use it as a way to express myself; not limited by lines on a page, where I can make illustrations in the margins, write non-linearly and get thoughts out of my head. I have volumes of these codices dating back to highschool. These thoughts and entries are rarely (if ever) shared with anybody, and are meant for my own processing—a safe place to reflect.
As mentioned by Lamb & McCormick (2020), text recorded in a codex has the affordance of being able to refer back to concepts made external. By fixing points of information on a page (or parchment, scroll, clay tablet), we create more space in our minds because we are relieved of the need to ‘remember’. We also create something that can be referred to by others, and promotes further inquiry and reflection through space and time. Although I generally don’t share my journal entries with others, I do appreciate the ability to look back at my reflections from different ‘snapshots’ in my life to see how things have changed.
One can see the remnants of handwriting (or cursive) in my printing. This blend between both printing and handwriting serves as a ‘personalized font’, and is not readily replicated in word processing applications, or even in letterpress technologies. It could be argued that a human element is lost when we use technologies to replace writing by hand. This is also seen in how errors/mistakes are addressed. I simply scribbled out a few words that I wanted to change, but in using computer mediated word processors, these changes would be indecipherable and simply ‘deleted’. For the most part I don’t edit my personal journal entries, though. I think there is value in stream-of-consciousness style writing, especially when the intent is expression/reflection.
I write with water-insoluble pen now, at least for text journal entries, because there have been far too many times that I’ve spilled water in my bag and I’ve lost entries. Computer mediated print (especially from an inkjet printer) is susceptible to this same weakness. An affordance that computer mediated writing has over manual methods of writing is that it can be reproduced easily and saved in many places, which decreases the risk of elemental damage. Lamb & McCormick (2020) mention how books have been burned to destroy their lineage and evidence of their existence, but as soon as a text is published on the web, it’s almost impossible to get rid of it completely.
Often in my journal entries, I like to illustrate between thoughts, or contain thoughts in particular shapes. My writing is often not linear, and instead the page becomes a free play of space that I can follow my emotions, thoughts and instincts. Mechanized forms of writing can allow for this to a point (by using a Wacom tablet and digital stylus). However, more formal word processing applications like Microsoft Word or Google docs do not have these affordances readily available.
Lamb, R., & McCormick, J. (Hosts). (2020, May 26). From the vault: Invention of the book, part 1. [Audio podcast episode]. In Stuff to blow your mind. iHeart Radio.
Lamb, R., & McCormick, J. (Hosts). (2020, May 28). From the vault: Invention of the book, part 2. [Audio podcast episode]. In Stuff to blow your mind. iHeart Radio.
Task 3 – Voice to Text
The following is my voice to text story. I used my iPhone, opened a text to myself and used the microphone button to record it:
So for this activity, I had a bit of a challenging time trying to think about what to dictate to my phone, but I figured I’d share a bit about a festival that my partner and I are volunteering for next weekend. It’s called Heart Of The City arts and music festival and it gives an opportunity to intercity artists to showcase their arts on a large stage for some of them very first time there will be musicians of all types. Visual artists who are also doing workshops. And there’s also a beat poetry stage, which I usually like hanging out around The festival takes place in Giovanni Goto Park, which is in the Mick neighbourhood and Edmonton. It’s generally a rougher area of town but for this weekend it brightens up and is filled with festivities that all people are welcome to enjoy. There’s also opportunities for people in the neighbourhood to be vendors selling their wears art writing and creative expressions. This will be the festivals 20th year which is really cool to think about.
We’ve been volunteering with this festival since about 2014 and it’s really need to see how it’s evolved grown and changed over the years in previous years. I helped with the art direction and organization of the art tent and that was a really fulfilling position. I remember that year we had an indigenous beading workshop we made peace flags did record painting and made scenes. We had a local Macaulay resident teach yoga in the field during the music Acts and we also had an artist from the neighbourhood who makes large scale sculptures create a wire frame that community members would come and add paper mesh to. He ended up creating a large dragon piece that was about 8 to 10 feet long. It was so neat to see all the different people come along, and add their own piece to the dragon sculpture and eventually by the end of the festival, everybody was adding their own paint to the skin of the dragon each year. There’s a different theme. This year‘s theme is reboot and it should be interesting to see what kind of interpretations there are of that in the music art and poetry that takes the stage.
This task was interesting for me. I generally do not use voice to text technologies, so this felt a little awkward to do. The first thing I noticed is that, whenever there was a natural pause in my speech, sometimes the technology would note it as the end of a sentence, and sometimes it wouldn’t. It would sometimes incorrectly indicate the end of a sentence based on the words I used, or maybe based on where I took a breath in my speech. For instance, in this passage, the end of the thought should have been at the end of the word dragon: “It was so neat to see all the different people come along, and add their own piece to the dragon sculpture and eventually by the end of the festival, everybody was adding their own paint to the skin of the dragon each year. There’s a different theme.” In all honesty, there were awkward pauses as I completed this assignment because was a little distracted watching the text appear as I spoke.
The text deviates from written English in a few ways. Many of the proper names of places were misspelled, and this likely has to do with the way I pronounce them (or the fact that the voice to text technology has not heard these terms before). For instance, Giovanni Goto Park should be Giovanni Caboto Park. Mick/Macaulay is a neighbourhood in Edmonton, and it should be McCauley. If another local person was listening to me talk about this festival, I don’t think there would be any question about which park or neighbourhood I was talking about. However, having it captured in text incorrectly, due to my pronunciation, could misdirect and confuse a reader who’s unfamiliar with these places.
Another way the text deviates from written English is in the punctuation (or lack thereof). What one might identify as a ‘run on sentence’ in the written form is far more acceptable and understood in oral speech. I notice that the text to speech functionality missed some periods and commas, but still capitalized a word because it is usually used at the beginning of a sentence. For instance, in this passage: “And there’s also a beat poetry stage, which I usually like hanging out around The festival takes place in Giovanni Goto Park, which is in the Mick neighbourhood and Edmonton.” This could have been related to the cadence of my speech—perhaps I paused less between the end of the first thought and the beginning of the second thought.
A few words were captured wrong, such as intercity instead of inner city, scenes instead of zines, and need instead of neat. Again, this likely has to do with the clarity of my pronunciation and the ability of the technology to identify and transpose words that are perhaps less commonly used in particular contexts or orders. But it underscores the differences in expression in aural texts versus written texts based on each individual’s linguistic qualities.
A scripted story would have probably followed more of a sequence. There would be a beginning, middle and end. Unscripted stories allow the speaker to jump around in time, follow intuition and interest, and spend more time on particular details. It would also include more formalized writing, and have less informal “ums” and “uhs” that people naturally interject into their stream of consciousness speech.
Oral storytelling allows for more personality, emotion, and animation by the individual telling it. An oral story is dynamic and may not be exactly the same each time it is told. It can also be influenced by the listeners (in the live environment). The listeners may ask questions, or have reactions to the story, which can impact the way the story is told. An oral story’s effectiveness depends a lot on the person who is telling it. Written storytelling is a static capture of what the author wishes to convey. It’s sequential, and lacks animation beyond the words written on the page. Each time it’s read, and regardless of who is reading it, it’s exactly the same. A written story has an existence beyond the person who wrote it, and lives well beyond the life of that person.
In oral storytelling, dramatic pauses, cadence of speech, emphasis on words, and the emotive quality of a voice is integral to how a story is received. This can be sometimes captured in text by using formatting. I am thinking of poetry that uses font style changes, spacing on the page, and bold or italicized words. However, text really cannot capture the nuances of a poem being spoken on a slam poetry stage; intonation, volume, rhythm, and even facial expressions that express the irony of a line in the poem are lost if only experiencing the poem in the written form.
Here is a great example of how spoken word lands differently than simply reading text. Kae Tempest, a notable poet/musician who I admire, recites a poem called “Getting On”. Listening to them speak their words, I truly feel something would be missing if one were to simply read this poem from a page in a book.
View this post on Instagram
Ong (1982, as cited in Haas, 2013) states that “sightbased text (written or printed texts) fosters contemplation, analysis and critique, whereas the sound-based temporal world of speech is totalizing; it pours into and envelopes the listener”. I might argue that with the advent of social media/video technologies, we are getting the best of both of these worlds. A recorded text like the one above incites contemplation and analysis, while also pouring into the listener/viewer.
Haas, C. (2013). The technology question. In Writing technology: Studies on the materiality of literacy (pp. 3-23). Routledge.
Tempest, K [@kaetempest]. (2023, April 23). Divisible by Itself and One is out today! [Kae Tempest reciting Getting On]. Instagram. https://www.instagram.com/reel/CriSadjImGA/?igsh=MXl0OXRxM3dyd3Jy