
Unsupervised classification relies on a Computer-based (automated) classification to group pixels with similar reflectance values into different classes.
Advantages:
- No extensive prior knowledge of the region is required.
- Likelihood of human error is minimized.
- Unique classes can be identified (which may be erroneously incorporated into other classes in supervised classification
Disadvantages:
- Mismatches between clusters and actual classes could occur.
- It is difficult to get just the right number of classes: too few means mixing real classes; too many means a headache to deal with.
- Analyst has limited control on the resulting classes and their identities (i.e. not appropriate if a specific classification system is to be applied).
- Spectral responses of classes can change over time; difficult to apply equally to multiple images.
CLUSTER analysis
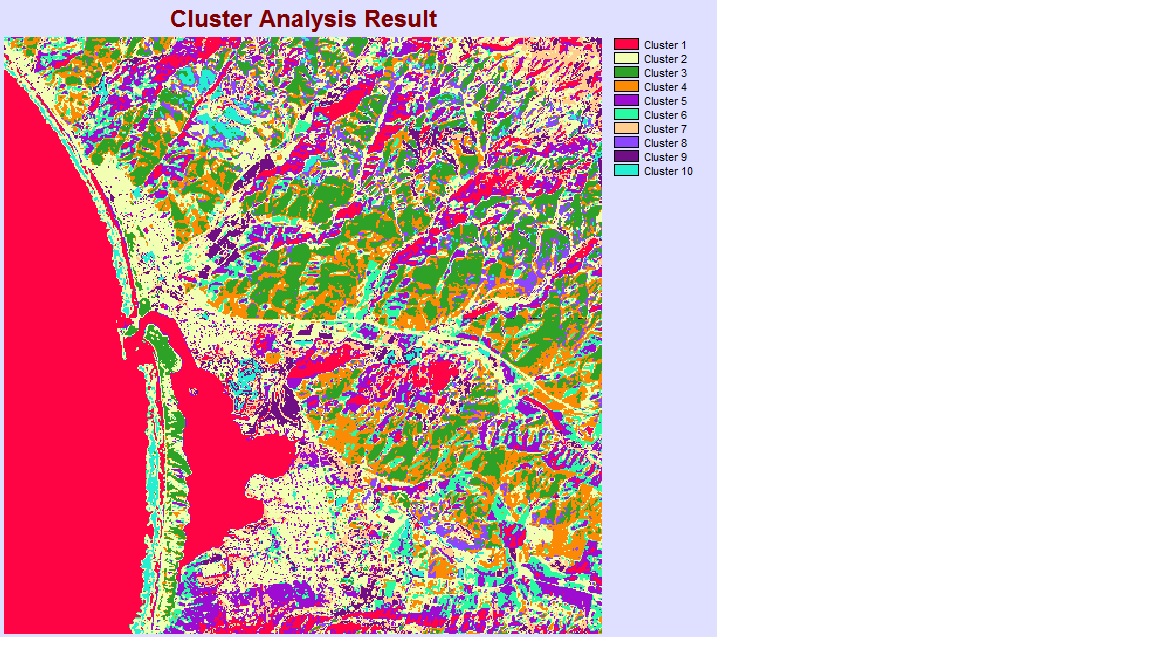
The analyst must assign meaningful names (e.g. water, urban, etc.) to the identified classes. In order to reduce the number of ‘relevant’ classes that are identified, the analyst must also set a threshold for the percentage of the total number of pixels in order to be considered as a ‘relevant’ class for the analysis.
ISOCLUST analysis
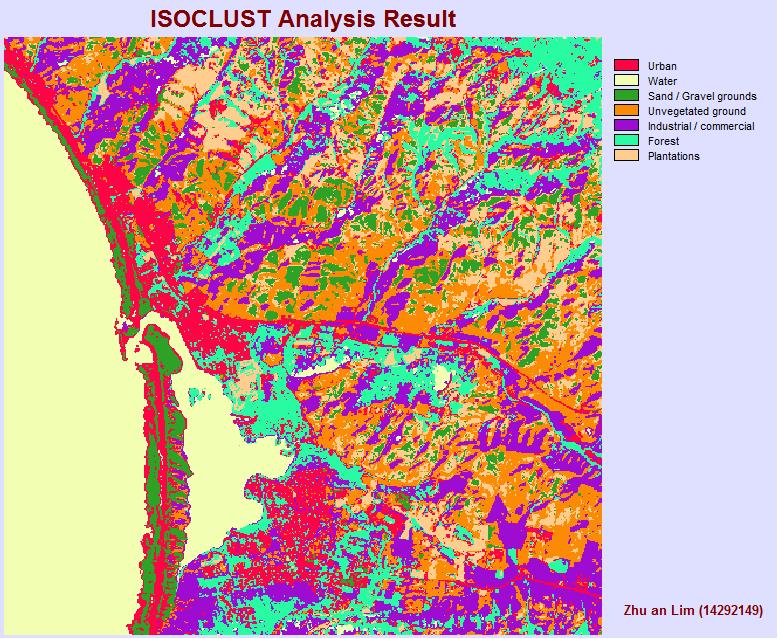
This method is similar to CLUSTER, and is considered as a unsupervised classification method as well. Both CLUSTER and ISOCLUST are hard classifiers, which creates a Boolean classification scheme — i.e. a pixel is either in the class (e.g., forest) or not.