Algorithms
I like both options provided in task 11 so just decide to be both. Each option reflects a fraction of how algorithms work, and even though I do not have the knowledge of how exactly it works, it is always interesting to go backwards and guess from my results.
Detain/Release
Among the 25 defendants, only four are suggested by the system (AI-informed decision) to release.
Two are more apparent (#3 & #23) as they are both low on all three categories – fail to appear (at the trial), commit a crime (again), violence (level).
If we assume all categories are equally important and attribute 5 to the high, 3 to medium, and 1 to low (level of risk), then calculate the total (as shown in the table below), we can see six cases (#6, #8, #10, #13, #16, and #17) have the second-lowest score (5).
However, only #16 and #17 are recommended to release.
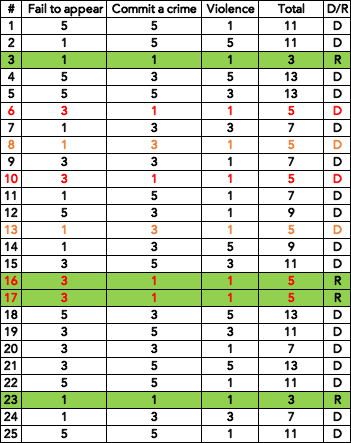
Even though the total score is 5, #8 and #13 have a medium “commit a crime” risk, whereas the rest have a higher “fail to appear” risk. Based on this, it is probably safe to say that “commit a crime” and “fail to appear” are not viewed as equally important to the system. The “commit a crime” category seems to be more important than “fail to appear,” probably associated with the fact that public fear will increase if the defendant commits another crime before trial.
The tricky ones are #6 and #10, as they have the same score in every category.
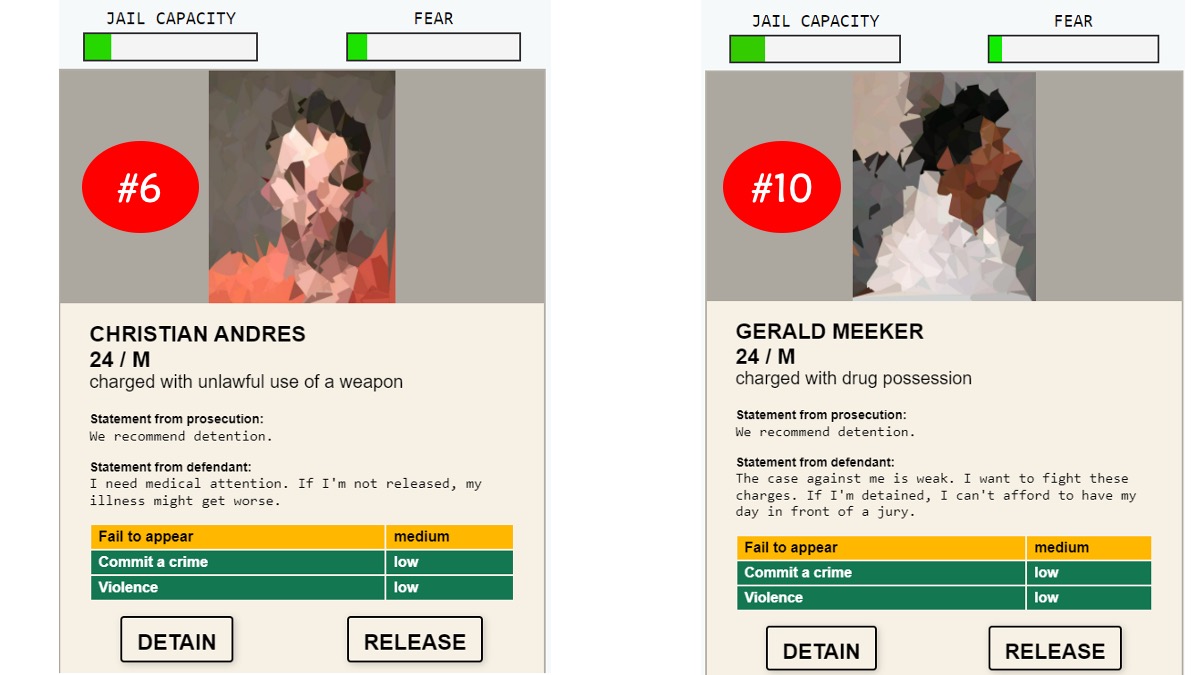

Compare the four defendants above. Here are my guesses of what the AI:
- As four are all males, it is hard to tell if gender is a determining factor here.
- #16 is 60 years old but charged with murder but still recommended to release, suggesting age is a determining factor.
- #10 and #17 can be viewed as in one age group (mid 20 – mid 30), charged with similar charges (drug trafficking and possession), but #10 looks like a person with dark skin colour, suggesting skin colour (ethnicity) is a determining factor here. This echoes the entire talk of the Crime Machine Part I (Vogt, n.d.), where the New York police station is targeting the black male group to meet their quota.
- #6 also looks like a person of colour but not sure if the filter may cause by the picture distortion. If it is not because of colour, another possible reason is that the charge of unlawful weapon use is considered more severe than drug possession.
As you may notice, I have not included how the “statement from the defendant” may affect the decision of detention or release. I think it requires another algorithm to tell if they are telling the truth in their statement before it can be assessed then influence the decision.
Compare my own choice to the AI suggestion, there are two obvious issues with my decision:
- The consistency in my decision is low. Halfway through the 25 defendants, I have to stop and think if I had encountered a similar situation before and how I decided to detain or release them. The longer the process is, the lower the consistency as we get affected by factors such as the tiredness of our own brain, the mental condition (e.g., excited and wanted to be very responsible, or tired and just wanted to get it done).
- The influence that environmental factors have on humans (i.e., me!). The information in the table is of value (high, medium, low risk), not the colour-coded system (environmental factor – may not be the most accurate name but reflects how this colour is irrelevant, the content is what’s important). However, these colours do significantly affect my decision. For example, the high risk highlighted by red has a more intense visual impact on me than the yellow for medium risk. Using my hypothetical rating system (the table above), I may detain a person who has one red and two green than a person who has two yellow and one green,, but their total scores will be the same using my own hypothetical scoring system (5+1+1 = 3+3+1).
Algorithms of Predictive Text
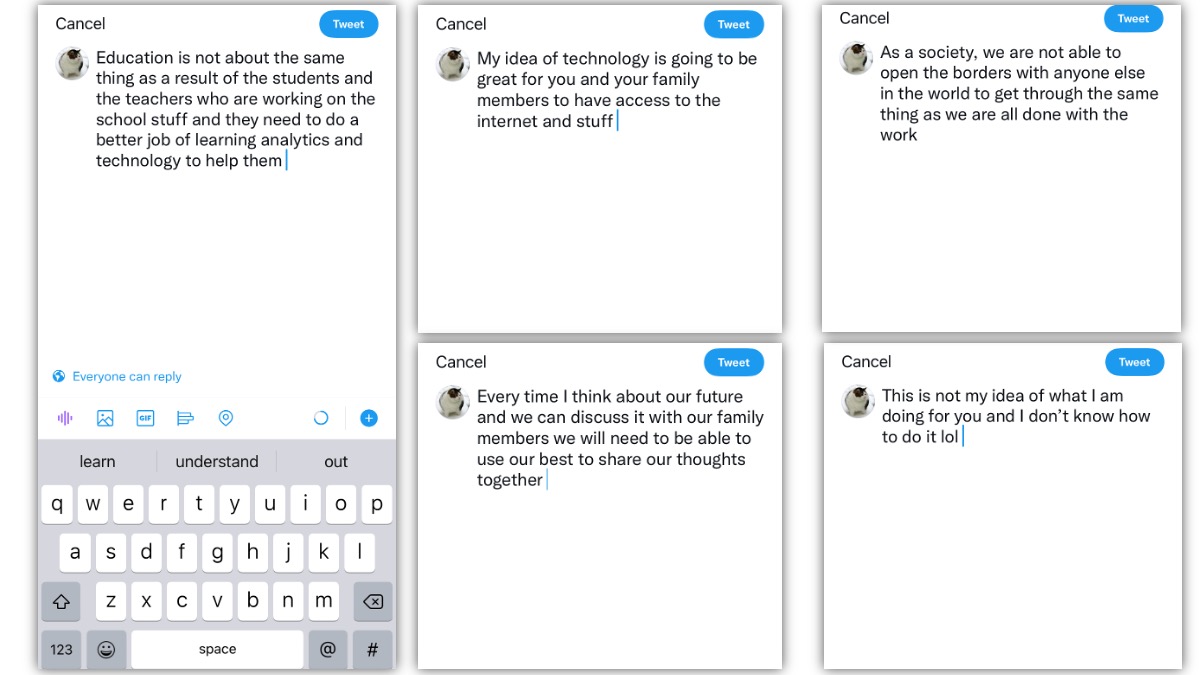
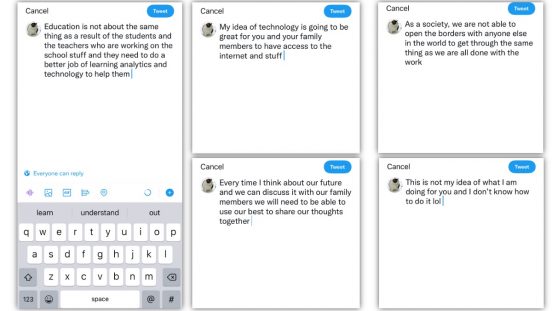
I have tried all five prompts, and honestly, none of it would be what I would write without the help of predictive text. Most of these textual products would be appropriate for blogs, and the last one would be for a text message. I was very hesitant when selecting these words from the predictive text options because all the three word options presented to me did not seem to get me to a complete sentence that is grammatically correct. This makes me wonder if the algorithm behind the predictive text allows it to pick up my habit of texting (e.g., my text messages have many grammatical mistakes due to my mindless typing and big thumbs, and some unwanted help from autocorrection).
Even though none of these sounds like me, I spot a few words I have recently typed. For example, learning analytics. I responded to Ernesto’s (our instructor) comment in task 9 and mentioned that I want to take the learning analytics course next year. I also asked questions about this course via text messages to another student and discussed this course with a few others. When I selected “learning” after the word “of”, “analytics” become the first options my keyboard presents me with. There are many words that can follow “learning”, if you search in Google, the predicted text in Google gives you learning skills, learning styles, etc. Therefore, I feel the “learning analytics” is what the algorithm picks up from what I have typed using the keyboard on my phone. Here are some other observations or my assumptions based on the observations:
- The algorithm behind the predictive text works excellent when the input is short and about things that I usually use the text message for, such as telling others I am “on my way” or making an arrangement “meet me at the…”.
- The prediction is probably based on what is commonly used by a large number of people. In other words, it is learnt via data analysis based on a lot of data. How does this data associate with me will determine how accurate the predictive text is to me. The language is English, so I assume the data is from native English speakers, so when you type in “a cup of,” it is likely to be followed by coffee or tea, and another beverage you often used with “cup.”
- How often I use a term will also affect the prediction. In a way, I think the algorithm has the ability to learn and incorporate the new most frequently used vocabulary from the user. The third option I had for “a cup of” is “course,” which I have never used such a combination. However, I use “course” frequently as I discuss my course project with classmates, course development process with my coworker, and when the algorithm can’t seem to find anything associated with “a cup of,” it gives me the most frequently used word.
- The three options also limited the choices. If there are more spots, I may see the word that I usually use to express myself. How to populate the top three options is another challenging process for the algorithm. I assume it is the frequency, and probably a mixture of the global frequency – the data source mentioned in (2) and my own most frequently used work as mentioned in (3).
Something to Think About
There are two major ideas behind this weeks learning resources, which are:
- If I may borrow from Dr. O’Neil, “we, the builder, impose our agenda on the algorithm” (Roman Mars, 2017)
- Most AIs are just powerful tools to find patterns and amplify these patterns to present us what it would look if the patterns are magnified as according to Dr. Vallor’ (Santa Clara University, 2018).
Apparently, we are the ones to blame. For imposing our agenda (with our bias) in the creation of the algorithm, and for populating all the data (with our bias) that the algorithm learns from.
Even though Dr. Vallor says the imaginary AI rules the world is not going to happen anytime soon, if it does, who is there to blame? Have we created more good than evil in the data we feed the algorithm behind the AI to learn from? Have we not built AI for generating information that benefits us financially but is not ethical? This all comes down to us, and probably a good practice to start the change now is to think what you say and do (in your life and online) will affect everyone you love in the future and be responsible for your words!
References
Roman Mars (2017). 274 – The Age of the Algorithm [Audio]. In 99% Invisible. Soundcloud.
Vogt, P. (n.d.). The Crime Machine, Part I. In Reply All.