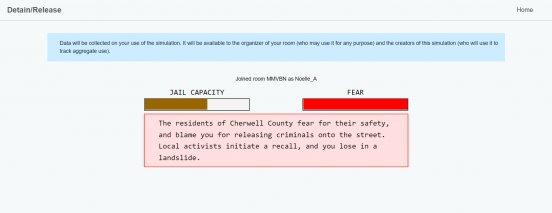
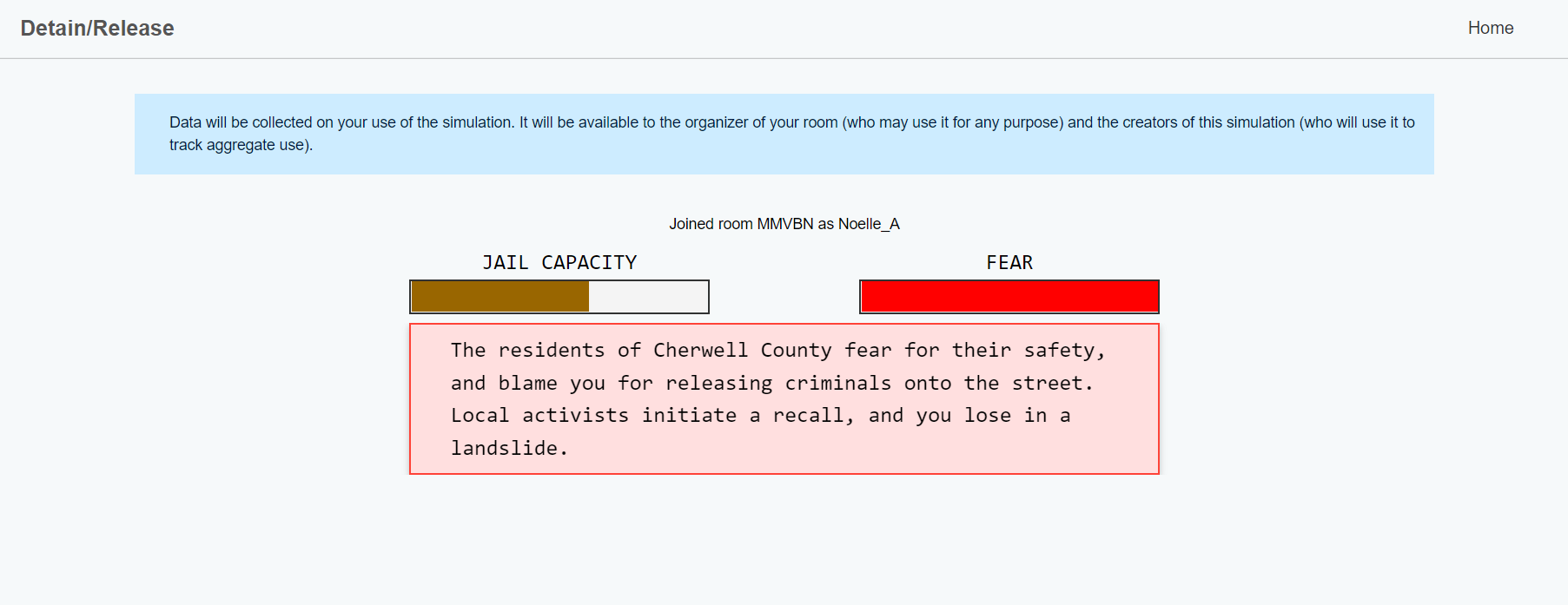
I’ve been thinking about this simulation all day and I’m still not entirely sure what to make of it. I think this speaks to the highly nuanced problems often seen in the justice system, which doesn’t bode well for algorithmic behavior intended to solve simple, repeated problems. The risk-assessment of each defendant didn’t always appear to line up with the charge, or with the prosecutor’s recommendations for their release or detainment. I would release a drug trafficker with a low risk of violence, only to discover they turned up elsewhere with a weapon. I also think I’m not so well-versed in the American justice system and I wondered why when one of the defendants I released didn’t show up again at their proposed time, my jail capacity bar went up. Were they arrested for being a no-show? The way the simulation unfolded might have reflected the chaotic nature of a system that is difficult to make sense of, and within which algorithms have only served to further muddy the waters.
I also maybe went through the simulation a bit too quickly. As I said above, I couldn’t readily distinguish patterns from my choices and I quickly lost track of who I had released until they popped up again after having done something else. I based my decisions solely on types of crimes and was exceedingly generous with my releases. If I could do it again, I’d have made better notes about my decisions so I could keep track of which defendants re-offended or no-showed. I didn’t expect so many to pop back up again later in the simulation. Although, at least in the case of no-shows, I’m not sure that the incidents of re-offence would have changed my mind about my initial decisions. If this is how algorithms are used in the real world to provide risk assessment, then it is surely concerning that this simulation felt a little bit random.
Given our reading and audio resources for this week, I was hoping that the simulation might include some of the data that was discussed regarding COMPSTAT such as geography or income level (Vogt). I found myself wondering about each defendant as they popped up on the screen. Which area of the county were they from? Would they be consistently low income? Were they perhaps previously arrested, making their risk assessment score disproportionately high in relation to the charge? As I thought about these factors, I made the decision to only detain those defendants charged with a violent crime such as murder, rape, or assault. I’m not suggesting this was fool-proof, or even wise given the number of people wrongly convicted in the criminal justice system. I was mainly trying to establish a pattern where defendants who committed crimes of a lower impact on the community would not be detained. Therefore, I think I released the rest (I was indecisive over one drug trafficker that was very high risk and I can’t remember what I decided). In other words, like in how we design algorithms to help us make these decisions, I decided on where to direct my attention (O’Neil, 2017). The public, of course, was not excited about my pattern of decision-making. But that’s okay (judges shouldn’t be elected, anyway).
Finally, in thinking beyond the simulation to the broader ramifications of relying on AI to inform important societal decisions, I come down firmly in the ‘no’ camp. I think the COMPSTAT example is just one of the many examples large and small that show that we don’t have a firm grasp on how machine learning algorithms grow and perpetuate. At least, we don’t know enough to determine the consequences of their activities on our decision making or behavior. In one very small example this week, Facebook’s algorithm was removing all posts related to Marvel’s Eternals which as some suggested could affect the film’s revenue (maybe, who knows). The broader point is that Facebook didn’t seem to know why this was happening – the algorithm had made its own choices. What happens if that problem arises during protests or during a disaster? On a much more serious note, even if we can readily identify a problem within the AI, as with COMPSTAT, it is very difficult to work out how to debias the system. For example, making machine learner better at understanding faces of marginalized groups so it stops mis-identifying folks ultimately also means feeding these systems more faces from people in marginalized communities. And why on earth would they want that? In fact, in terms of the terrifying potential of facial recognition and AI, this episode of John Oliver is seriously scary.
All that to say that we are relying on algorithms to help us make decisions that affect the ability of large portions of the population to live their lives with any kind of equity. Not only are we systemically biased in the real world through the institutions we’ve formed, or through the lenses we view people with, we’ve baked the bias right into the machines we now use to form decisions on justice, employment, and surveillance. My fear is that not only do we not understand what is happening with this data as it relates to machine learning, but that we also didn’t have a great grasp on it before machine learning was implemented. When it comes to social phenomena, it’s just not that easy to tease out causality, which means our ability to predict is likewise limited. Machines used for predicting are only as good as their data and it’s the same data we’ve always had – just way more of it all the time with the power to profoundly affect people in ways we can’t yet fully grasp.
References
O’Neil, C. (2017, April 6). Justice in the age of big data. https://ideas.ted.com/justice-in-the-age-of-big-data/
Vogt, P. (n.d.-b). The Crime Machine, Part II. In Reply All.