Exploring job statistics of librarians and archivists in America
by Mya Ballin & Liz Day
Objective
The objective of our info visualizations was to enable an individual to get an idea of the library, information science, and archives jobs in America over the past decade. We imagined that intended users would be those who are considering graduate school and want to know about what job prospects might be on the other side before committing, as well as those who are currently in school who are looking to get an idea of what their prospects will be upon graduation. Additionally, this resource could be potentially used by current librarians and archivists as a tool to discover where their current job sits in the context of jobs at large.
We wanted users to be able to achieve certain queries pertaining to their interests–geographic and professional (in a very general sense)–mainly those identification and comparison. Questions that we imagined users being able to answer included: What states employ the most librarians/archivists? Where can I be expected to be paid the most? What industry hires the most librarians/archivists?
To this end, interactive options are mainly related to filtering and selection, which we felt were adequate for the needs of the user in relation to understanding the data.
The data
All the datasets used in this project were sourced from the Bureau of Labor Statistics (BLS), a unit of the Department of the Labor, and under the purview of the US federal government.
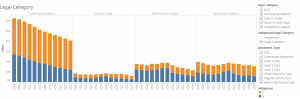
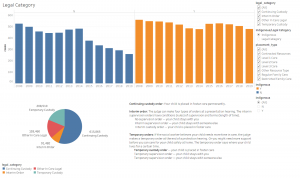
The national map visualizations, the comparisons of 2010 and 2019 wages bar chart, and the top and bottom 5 earners, work off of the same dataset which is a combined set of annual labor and wage statistics from 2010-2019 for each individual profession. This combined set provided us with many more attributes (27) than were needed to produce any visualizations. The California view uses identical data attributes to the national wage and job availability data set but goes more granular, by looking at the same data broken down to region, instead of counted at the state level. All components of the infographic portion of the vis (pie chart, job breakdown, word map) use data from the larger job grouping of “Educational Instruction and Library Occupations Group”, this data set looked at the saturation of librarians and archivists, compared to other professions under the same occupational group according to the BLS.
Data wrangling was mostly spent integrating different data sets, as the data obtained had a dataset for each year used. There are a number of null values for occupation type and years without any statistically significant data, this is only obvious when the visualizations are viewed by specific year or occupation type.
Tools
The primary tool that we used to transform the data into an information visualization was Tableau. As we had become familiar with using this tool to analyze fairly large data sets through the course of the class, it felt natural to gravitate towards this program for our final project. Tableau provided key capabilities that allowed us to create both the interactable and encodable elements through which we imagined our objective could be achieved.
The easy way in which data points can be grouped together proved to be particularly useful when we sought to create the distribution of wage graphs, as it meant that we did not have to manually create and populate a new column of data. Because of the national nature of the dataset, doing so would have been incredibly time consuming, but Tableau allowed us to create this very helpful visualization simply through its own capabilities.
The ability of Tableau to create dashboard views turned out not to work in our favor, as embedding a dashboard in our website skewed the dimensions of each individual vis in such a way that it no longer was particularly effective in its presentation. Additionally, the program’s geographic properties, while helpful in creating choropleth maps, is dependent on very rigid maps or the ability of the user to acquire geographic polygons. If this is readily available, such as the example that we saw in class where polygons were provided by a governmental department, this isn’t such a hassle, but if such information is not easily discoverable, Tableau’s workarounds do not feel adequate. This proved frustrating on two separate occasions for this project: one in which we were interested in creating a cartogram and one when we were interested in only including one state (California) in our vis. After trying several solutions for both of these desired vises, we decided that the hoops that would have to be jumped through could not be justified when the time could be spent on making a much more readily possible vis as effective and expressive as possible, and so those ideas were dropped in favor of our current vis idioms.
In addition to Tableau, we also used infogram to create various visualizations. The program’s ability to offer a wide range of preset idioms that could be customized to ones data was incredibly useful, and it meant that we had access to a lot of idioms that we might not have otherwise thought of or considered. The person breakdown chart is an example of this.
Infogram’s animations and smooth aesthetic make it an incredibly attractive interface that is easily accessible for non-designers and programmers, and one that increases the attractiveness of the visuals for the user. However, some of the ways it makes itself easily usable also makes it a little too rigid. For example, when trying to assign state to hue, it turned out to be surprisingly difficult to ask Infogram to do so when it wasn’t the x or y axis. As a result, each bar had to be assigned its own color individually and the charts for each profession had to be separated from one another. Gradients were not an automatic capability either, which made the creation of the variation in saturation for the word cloud more difficult than when we had used the word cloud tool for the in class exercise.
The last tool that we used in order to tell our story was Weebly. This was incredibly effective in allowing us to actually lead the user through a narrative. One downside of this, however, is that the heavy amount of embedding that needed to occur in order to bring everything onto one page means that it takes a long time for the site to load, particularly when it comes to the Tableau vises. Additionally, dimensions of infographics proved to be slightly difficult to manage, and therefore a lot of tweaking was required in order to produce a completely effective product.
Analytic steps
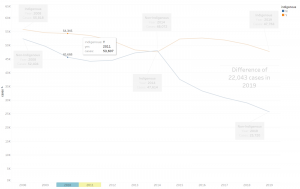
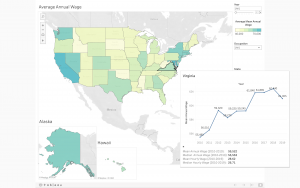
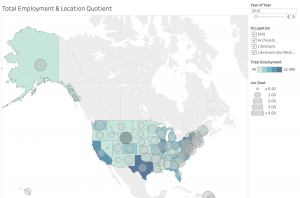
The BLS provides occupational profiles, but in the form of static maps and charts, and disjointed by occupation and year. We decided that we wanted to create similar maps views but, both integrated and interactive. Since the key to the project was showing the differences (or similarities) by state, the project began with two map views (one showing wage data, the other showing job numbers data). These two visualizations exist in an interactive form providing a great deal of data on wages and job numbers over a 10-year period. There are also two animated versions of these maps, to simply show national changes over time, with a less granular view of data.
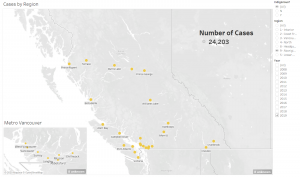
From these map visualizations we were able to build upon what narrative we wanted to tell and what visualizations would support that. We looked to see how the occupations of librarians and archivists compared to other professionals in the same industry group according to the BLS. And, wanted to draw attention to what we had determined was pertinent information for the viewer (mainly top and bottom five earners by state, and overall annual wages by number of states). This information is already provided in the initial map view, but we felt it important to bring attention to. Finally, as residents of California, we felt it important to be as granular as possible by looking at the same wage and job number data, but under the lens of metropolitan regions within a state.
There was no specific argument trying to be presented prior to beginning the project. But, upon creating the initial national map visualizations, we concluded that wages and job numbers have been going up historically. We wanted to see how this wage information compared to other professionals and how LISA professionals compare to colleagues of similar fields. The goal is to have the user interact with the various infoVises and for themselves to conclude if either of the two professions are viable for them based on potential earnings and potential job availability.
Design process and principles
The vis idioms we selected were specifically chosen based on our desire to create a collection of graphics that explored a variety of different attributes including space, time, and hierarchy. We chose to use choropleth maps and, in our total employment map, a version of a cartogram in order to expressively and effectively communicate the data. We chose to use maps because the key of our data was based on state, and in order to represent it most effectively, using position on a common scale is considered to be the most effective. Because, as previously mentioned, creating a true cartogram was not possible given the time restraints and difficulties with creating polygons, using a version that utilized a form of area enabled us to utilize another magnitude channel that is relatively high on the effectiveness scale.
Color scheme was another key design element that we thought about. Tableau offers a large range of presets, but many of them transition from one hue to another through white, which can be kind of confusing if you have a lot of items that would be in the middle ground. The green-blue preset spectrum, however, is very clear in its transition and does not create the same kind of confusion that many of the color to color spectrums do, and so we elected to use this palette for our most important choropleth map.
For the infogram visualizations, we tried to use hue to create a pop-out effect by incorporating primarily luminance based distinctions between objects that were not our target, and using a completely different hue just for the most salient points. Color choices were made using guidance that explained distinctions visible by those who are colorblind in order to hopefully ensure that the visualizations are accessible.
The Story
The overall intention of the project is to provide burgeoning information professionals – mainly aspiring Archivists and Librarians, about the general landscape of wages and job prospects in the United States. With questions like: will I be able to get a job after I graduate? Are there library jobs back where I’m from? Is this occupation going to be able to financially provide for me? As a future archivist, what industry will I find a job in?
By presenting geotemporal wage and job availability in the form interactive maps (indicated by color gradation, and shape size), users are easily able to make assessments of wages nationally over time, and the number of employed professionals over time. Through this the user is able to then query specific locations, time periods, or occupations to narrow down granular data that would interest them specifically.
Beyond national wage and job statistics, the infographic portion of the project provides further information for LISA professionals as compared to other colleagues that fall under the same “Educational Instruction and Library Occupations Group”. It shows previously provided information (wage data by state) in a bar graph vis, to be able to compare states with the highest and the lowest wage earners.
Finally, the project looks specifically at the state of California (home-state of both of us), providing a different view of the statistical data from the initial national map, by breaking wages and number of professionals employed by region. This gives the user, in this specific case Mya and Liz, an understanding of what they can expect as far as income and job availability in their home states, compared to what is considered a ‘living wage’.
After viewing the entire project, we hope the viewer has made judgments on where they might get a job, how much they might be paid, and their status compared to other similar professionals.
Pros and cons of your designs
The strength of our designs is their ability to allow users to get both geographic and temporal perspectives easily. The implementation of animation and the utilization of the tooltip function to show not only single data points, but state-specific graphs means that the visualizations are highly capable of answering multiple questions that a user might have.
However, that being said, the strength of our project as a whole relies on our ability to include a fair amount of explanation and narrative, which means that the visualizations are reliant on a certain amount of context. This is the case for any visualization, but it could certainly be said that certain idioms and vises do a better job of creating story on their own. Our decision to create vises that utilize narrative outside of themselves means that the project must come in a package in order for it to be at its most effective.
Another con of our design, or perhaps just of our data, is that because we focused on this one set that did not have librarians and archivists centrally in mind when it was created. There were a lot of questions that we had about methodology–such as whether considerations for contract/temporary work had been identified–that we could not answer and would perhaps have been considered in the context of profession-specific data. That being said, we did try to find if such sets might be available, and it did not appear to be the case. As a result, working with this data is probably the most informed we could be. Similarly, the MIT Living Wage Calculator, while technically accurate, also presented some interesting conclusions. For example, while using the data we concluded that it would be possible to live in the Bay Area on the wage presented by the BLS for the area, both project members were highly skeptical of this actually being a reality.
Include embedded visualizations or snapshots and links to public websites (e.g. Weebly, Wix, Tableau Public, Infogram, Canva, etc.) where your infovis can be https://libr514jobs.weebly.com/found.
All visualizations can be found embedded into our project website: https://libr514jobs.weebly.com/
References
Bureau of Labor Statistics. Librarians and media collections specialists. (n.d.). Retrieved from https://www.bls.gov/oes/current/oes254022.htm
Bureau of Labor Statistics. Archivists. (n.d.) from https://www.bls.gov/oes/current/oes254011.htm
MIT Living Wage Calculator. Living Wage Calculation for San Francisco-Oakland-Hayward, CA. Retrieved from https://livingwage.mit.edu/metros/41860