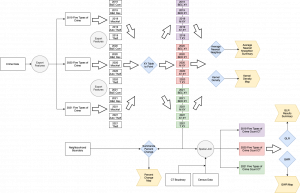
All data and features were projected to the standard projection used by the City of Vancouver – NAD 1983 UTM Zone 10N. And all analyses were performed on ArcGIS Pro 2.9.2. Every analyses required the crime data that has been parsed by each year and crime types to be converted into points using the XY Table to Point tool. The study area maps were always clipped to an outline of either the neighbourhood boundary or the census tract boundary. The base layer was excluded from the clipping. All the statistical results were done using Excel and the crime counts were obtained from the automatic summary in ArcGIS.
- Summarize Percent Change Analysis: Once we have transformed table crime data into physical points of X and Y locations, we used the Summarize Percent Change in the Crime Analysis tool to determine percentage crime change from 2019 to 2020 and 2019 to 2021. The input features was the neighbourhood boundary shape file and the XY points of crime. To add more visual data to the resulting maps, labels were added using the expression “Round($feature.PERC,1) “%” + TextFormatting.Newline + $feature.CUR_CNT + “from” + $feature.PREV_CN”. This analysis can be quite standard in crime statistics and was performed to distinguish the high and low historical numbers by displaying a percentage change (Wheeler, 2016). There are many opponents to this method, claiming that when used for crime counts, the possible swings in the random data and outliers can unjustifiably distort the data and the audience’s interpretation (Wheeler, 2016). However, we are observing only a short-term of 3 years of study period and the outlier in this study would be COVID itself, causing extremities in the fluctuation of crime counts.
- Average Nearest Neighbor Analysis: Each XY crime data was used for this analysis using the Euclidean method. The Nearest Neighbor analysis excels in assessing the distance relationships between the density of different recorded crimes (Pian & Menier, 2019). This analysis would effectively show us if whether the crime data is clustered, dispersed, or random.
- Kernel Density Analysis: Because clusters were found in the Average Nearest Neighbor Analysis, Kernel Density Analysis was performed to examine the location and the patterns of these clusters. The XY point crime data was input into the Kernel Density tool with population field of None, output cell values to Densities, and method field to Planar. The data classification under Symbology was changed to Geometric Interval and for the temporal comparison purposes, the density score classification using Geometric Interval with the highest max was replicated and applied to the same crime type in different years. The various methods of point pattern analysis like the Kernel Density or the Hot Spot Getis-Ord Gi* are one of the most fundamental steps in spatial and crime analysis (Kalinic & Krisp, 2018). The Kernel Density analysis is perfect for detecting hot spots and the intensities of highs and lows. Nuances and patterns can be observed from this analysis to make estimations and predictions (Kalinic & Krisp, 2018). For this study, only the Single Kernel Density was performed with one variable of crime. It can be expected that crime would be higher in high populated areas and to avoid this, the Dual Kernel Density is used to normalize the data. The Dual Kernel Density uses two variables, however, for this scenario, since we are already comparing multiple years as a variable, the normalization has already been done in that regard. This is why the Dual Kernel Density was forgone.
- Generalized Linear Regression: To observe crime and its relationship to multiple variables all five crime types had to be combined into one as observing the variables to each crime per each year would be too redundant and tedious. For this reason, the XY crime points were spatially joined to the census tract boundary file to create a Join_Count containing all the crimes within each CT. This count field was then normalized using the size of the area by mathematical division. The census data table containing median income, unemployment rate, total population, population age 15~64, and population age 65+ was joined to the CT boundary file with normalized crime count. Population age 15~64 and population age 65+ was normalized using the total population by also mathematical division to create two population density fields. Using the Generalized Linear Regression tool, the dependent variable was set to the five types of crime that has been normalized and the explanatory variables were the median income, unemployment rate, and the two normalized population age groups. Instead of the model type of Continuous (Gaussian), Count (Poisson) was applied as we already have the discrete data that are contained in each CTs. Normally, a Moran’s I spatial autocorrelation analysis would be performed after GLR using the residuals produced, however, several cluster analysis like the Average Nearest Neighbor and Kernel Density was already performed, so the Moran’s I was omitted. Although Average Nearest Neighbor uses distance relationships and Moran’s I measures spatial autocorrelation based on attributes, the results are similar in showing clusters. Exploratory Regression was also left out because of the limited variables that were already decided to be used. Regression analysis is often used in spatial analysis to model, examine, and explore spatial relationships to explain and identify the factors in observed spatial patterns (Esri, n.d.). GLR is one of the most common global regression models while also being a proper starting point for all spatial regression analyses. GLR is always recommended before conducting a local Geographically Weighted Regression and those same variables should be used to conduct the GWR. GLR uses an a-spatial format and a single regression equation that provides a global model of the variables (Charlton et al., 2006).
- Geographically Weighted Regression: After detecting significant variables from the global GLR, those variables were input into the GWR tool. The various fields remained the same as the GLR but median income and unemployment was removed in the explanatory variables except for the year 2019. The Neighborhood Selection Method of Golden Search was used with the Minimum Number of Neighbors set to approximately 10% of the data and the Maximum Number of Neighbors set to approximately 50% of the data. The Local Percent Deviance (often local r-squared value in Continuous Gaussian), was modified as Graduated Symbols in the Primary Symbology and Quantile data classification with three classes representing low, medium, and high was used. This Local Percent Deviance was overlayed onto the GWR maps for visualization and analysis purposes. Because of GLR’s global and a-spatial nature, it can be problematic when applied to spatial data as the process in question is assumed to be constant over all space (Charlton et al., 2006). To avoid this, GWR was performed to analyze local nuances and relationships that vary over space.