Présentation du projet
Les 12 modules proposés correspondent à 12 enregistrements de locuteurs francophones, réalisés dans diverses situations et traitant de sujets variés. L’accent est mis sur l’AUTHENTICITÉ: il ne s’agit en aucun cas de matériel adapté, expurgé, simplifié puis lu à voix haute, mais de documents “pris sur le vif”.
La plupart des enregistrements proviennent du grand corpus de français parlé compilé par le Groupe Aixois de Recherche en Syntaxe de l’Université de Provence (Aix-Marseille I) de 1977 à 1995: Lentilles, Accident de voiture, Adoucisseur d’eau, Éducation sexuelle, Guerre d’Indochine, Résidence universitaire, Vie parisienne, Chasse au sanglier, Belfast.
Les autres (Couches lavables, Œufs anormaux, Agence matrimoniale) ont été recueillis sur divers médias (radio, télévision).
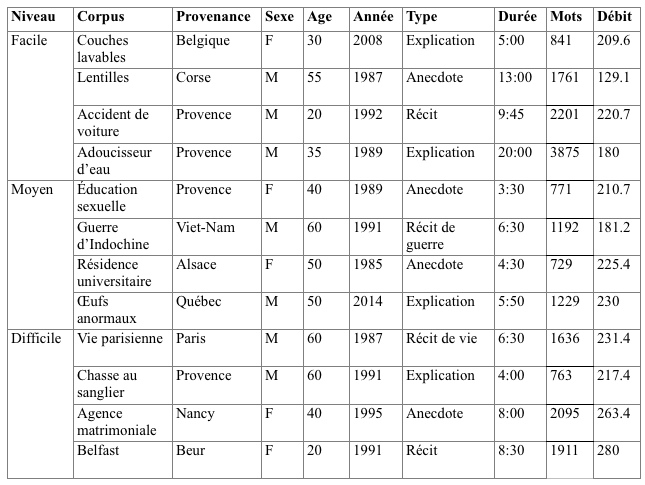
La longueur moyenne des enregistrements est de 5 minutes, avec quelques exceptions. La durée totale du corpus est de 95 minutes et correspond à une transcription de 19000 mots. Le tableau suivant présente une vue d’ensemble des douze modules, avec des informations sur la provenance géographique, le sexe, l’âge du locuteur principal, l’année de l’enregistrement, sa durée, la longueur de la transcription (nombre de mots) et le débit moyen du locuteur (en mots/minute).
Je remercie Adeline Caute qui m’a aidée à monter ces modules en ligne, grâce à une subvention de UBC. Je remercie également Juliet O’Brien et Joël Chauvin qui m’ont montré comment présenter mon matériel dans WordPress.
Le degré de difficulté des modules varie selon le débit et l’accent régional des locuteurs ainsi que selon le registre de leur discours. Leur ordre correspond à un degré de difficulté croissant.
Chaque module comprend un article principal qui consiste en une présentation détaillée de l’enregistrement suivie de son découpage en séquences (avec titres et résumés). Chaque séquence renvoie à une transcription intégrale dans laquelle des commentaires apparaissent en “Mouse-over text” sur les parties en couleur: bleu pour les commentaires de vocabulaire, rouge pour les commentaires grammaticaux et vert pour les commentaires stylistiques.
Les transcriptions sont aussi fidèles que possible et tout ce qui est prononcé est retranscrit. Cependant, elles présentent tout de même quelques écarts par rapport à la version sonore:
– Le choix de l’orthographe oblige à une certaine normalisation. La plupart des phénomènes de prononciation (allongements, élisions, prononciations déviantes) disparaissent des transcriptions faute d’outils adéquats pour les représenter systématiquement. Les amorces (mots non terminés) sont notées avec un tiret à la troncation: les enf-, amorce de les enfants. Malgré les écoutes répétées, il arrive que des segments restent incompréhensibles; ils sont notés par X. Dans le cas où on ne peut pas décider entre deux transcriptions possibles, on présente les deux options entre barres obliques: /et, mais/, /j’étais, j’ai été/. Un soulignement sous une consonne indique que celle-ci est prononcée: je l’aime plus. Une petite vague sous le texte indique la présence d’une liaison notable (liaison rare ou atypique) alors qu’une petite croix note l’absence d’une liaison fréquente.
– Le choix de la ponctuation crée lui aussi de la distance entre le texte écrit et la version sonore. La ponctuation est en effet une aide à la lecture plutôt que l’expression des phénomènes d’intonation de l’oral. La ponctuation forte coïncide en général avec les marques de fin d’énoncé (comme l’abaissement de la voix), mais les virgules sont plutôt utilisées pour faciliter la compréhension et ne correspondent pas nécessairement à l’intonation du locuteur. De même, les points de suspension sont utilisés systématiquement dans les cas d’hésitation et ne correspondent pas nécessairement à une pause du locuteur. Seules les pauses vraiment notables des locuteurs sont notées avec un double tiret.