I feel remiss that, in a blog called “socially speaking” with a computational linguistics joke up there in the banner, that I haven’t actually touched on any of the linguistics of social media. Let’s fix that:
A major field in the study of language is corpus linguistics. Its methodology revolves around the creation and use of large databases, called corpora, containing thousands if not millions of transcribed utterances and passages of written material. Copora are typically indexed down to the word and heavily encoded with metadata to allow researchers to search for subsets in the data that can be used to test a hypothesis about the use of language.
One of the largest handcrafted corpora is COCA, the Corpus of Contemporary America English. COCA was developed around 2008 by researches at Brigham Young University, and continues to grow. The size of COCA is only possible because of the volume of American English text available online — it was originally built with, of all things, Internet Explorer — but COCA doesn’t actually include any natively online content. The corpus was built as a retrospective, balanced, and American corpus. The corpus archives data from back to 1990, and splits the data in each year evenly between the five genres it includes. In 1990 there simply wasn’t enough internet communication to make up an equal percentage of the data, especially if you limited to American sources (if you could even tell), so it was declared out-of-scope for the project.
Still, the COCA is a behemoth. It has 520 million words from sources spanning 25 years, divided evenly between transcribed speech, fiction, popular magazines, newspapers, and academic journals. The corpus comprises some 190,000 texts in total. The use of the data is free to the public, you can check out their search interface here. For most of my linguistic training, it was one of the best — if not the best — English-language corpora.
Compare that to this Facebook corpus a group of researchers generated just for their own research. It comprises 700 million words in it contributed from 75,000 volunteers (15.4 million facebook status updates). They also got every volunteer to take a personality test. I can’t even.
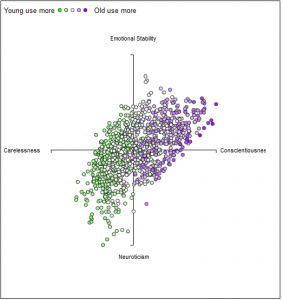
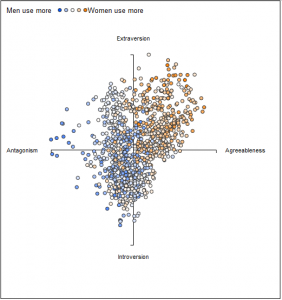
They’ve published some neat visualizations for their data on the links between word use, personality, age, and gender. It brings new meaning to “word cloud.”The power in these corpora is how easily they can be produced, and how easily their contents can be statistically manipulated and compared. Researchers are not only distributing their data sets, they’re sharing the code they used to collect them! (one such code release amusingly attempts to coin the term ‘tworpus’ for a twitter corpus)