
Multiple recent studies have used random forest machine learning for classifying wetlands (Liu et al. 2011; Millard & Richardson, 2013; Corcoran et al. 2015; Franklin & Ahmed, 2017; Halabisky et al. 2017; Amani et al. 2019; Bourgeau-Chavez et al. 2017; Mahdianpari et al. 2019, Merchant et al. 2019). It is simpler than some other classifying machine learning techniques and still provides high accuracy. Other benefits of machine learning are that it reduces the risk of overfitting that comes from using single decision trees and can maintain accuracy when a large portion of data is missing.
What exactly is machine learning?
El Bouchefry & de Souza (2020) and this website provide a good introduction to machine learning and the various types. To summarize, machine learning is a type of artificial intelligence that learns from doing and can improve its results this way. It uses algorithms (a series of decisions made by a computer or a set of rules followed to come to a decision) to build a model that can recognize patterns and classify high-dimensional data. There are two types of machine learning techniques: supervised and unsupervised. Supervised means the algorithm is shown data prior to making predictions and can classify new data based on the previous data. Unsupervised means that it is making predictions without a training data set. In the case of wetland classification where there are pre-determined wetland classes, supervised is the preferred method. This requires a training dataset, which may have to be collected from the field before hand. In their review of wetland remote sensing, both Ozesmi and Bauer (2002) and Guo et al. (2017) provide a good overview of supervised versus unsupervised classification methods.
Figure taken from: https://www.section.io/engineering-education/introduction-to-random-forest-in-machine-learning/
What is Random Forest?
As many decision trees as you want. Random forest (RF) machine learning is a supervised learning algorithm that uses multiple decision trees and then takes the majority vote for the final output. When using decision trees you have to be cautious not to overfit your model with too many parameters; however, if there are enough trees using the random forest technique, this is less likely to happen. If you have too many trees, the model will be too slow and ineffective. This post has some good info about what a random forest is.
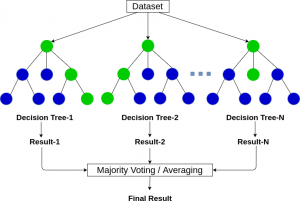
Figure taken from: https://www.analyticsvidhya.com/blog/2020/05/decision-tree-vs-random-forest-algorithm/
You can modify various hyperparameters to increase your predictive power. Hyperparameters include the number of trees, the maximum number of features, the minimum number of leaves required to split an internal node, the number of processors RF is allowed to use, the randomness of the model (to make it replicable or not), and whether or not you want to cross validate on your dataset. One great feature of Random Forests is that you can get an output showing feature importance, which tells you how much each feature (or parameter) reduces the impurity of your data across all trees – basically, how effective your parameter is at classifying your data. Using this you can fine tune your model to eliminate useless features or parameters that might cause overfitting.
There are a few common terms that come up when using RF modelling that I will define now. First is the Gini Index, which is a way to calculate how good each node classifies (or splits) the data. Second is bagging (bootstrapped aggregation). RF is a type of bagging algorithm that reduce complexity of models that overfit the training data. Several bootstrap subsets of data are used to train the model and the remaining data is referred to the out-of-bag (OOB) dataset. The OOB dataset is used by the model to evaluate its own performance. Specifically for RF, random subsets of features are also used in addition to the bootstrap samples for training the individual trees. This allows each tree to be more independent, which improves predictive performance. This is compared to just bagging, where each tree is provided with the full set of features. Note that in traditional bagging, the trees are not independent of each other since all the original predictors are considered at every split of every tree. Underlying relationships cause the trees to be very similar to one another. Random forest eliminates the similarities but introducing randomness into the sampling.
A good run through of random forest can be found here: Random Forests · UC Business Analytics R Programming Guide (uc-r.github.io)
Classification Accuracy
Supervised image classification methods require a training data set to distinguish between classes. It is important that each class is represented sufficiently in the training dataset. If one or more untrained classes exist on the landscape, the accuracy of a classification or resulting map may be compromised. G.M. Foody (2021) explores this phenomenon and the hazards of classification accuracy in greater detail in his paper Impacts of ignorance on the accuracy of image classification and thematic mapping.
…more to come in next post: random forest modelling in R
References
Amani, M., Mahdavi, S., Afshar, M., Brisco, B., Huang, W., Mohammad Javad Mirzadeh, S., White, L., Banks, S., Montgomery, J., & Hopkinson, C. (2019). Canadian Wetland Inventory using Google Earth Engine: The First Map and Preliminary Results. Remote Sensing, 11(7), 842. https://doi.org/10.3390/rs11070842.
Bourgeau-Chavez, L. l., Endres, S., Powell, R., Battaglia, M. j., Benscoter, B., Turetsky, M., Kasischke, E. s., & Banda, E. (2017). Mapping boreal peatland ecosystem types from multitemporal radar and optical satellite imagery. Canadian Journal of Forest Research, 47(4), 545–559. https://doi.org/10.1139/cjfr-2016-0192.
Corcoran, J., Knight, J., Pelletier, K., Rampi, L., & Wang, Y. (2015). The Effects of Point or Polygon Based Training Data on RandomForest Classification Accuracy of Wetlands. Remote Sensing, 7(4), 4002–4025. https://doi.org/10.3390/rs70404002.
El Bouchefry, K., & de Souza, R. S. (2020). Chapter 12 – Learning in Big Data: Introduction to Machine Learning. In P. Škoda & F. Adam (Eds.), Knowledge Discovery in Big Data from Astronomy and Earth Observation (pp. 225–249). Elsevier. https://doi.org/10.1016/B978-0-12-819154-5.00023-0.
Foody, G. M. (2021). Impacts of ignorance on the accuracy of image classification and thematic mapping. Remote Sensing of Environment, 259, 112367. https://doi.org/10.1016/j.rse.2021.112367
Franklin, S., & Ahmed, O. (2017). Object-based Wetland Characterization Using Radarsat-2 Quad-Polarimetric SAR Data, Landsat-8 OLI Imagery, and Airborne LidarDerived Geomorphometric Variables. Photogrammetric Engineering and Remote Sensing, 83(1), 27–36. https://doi.org/10.14358/PERS.83.1.27.
Guo, M., Li, J., Sheng, C., Xu, J., & Wu, L. (2017). A Review of Wetland Remote Sensing. Sensors, 17(4), 777. https://doi.org/10.3390/s17040777.
Halabisky, M., Babcock, C., & Moskal, L. M. (2018). Harnessing the temporal dimension to improve object-based image analysis classification of wetlands. Remote Sensing, 10(9), 1467.
Liu, H., Bu, R., Liu, J., Leng, W., Hu, Y., Yang, L., & Liu, H. (2011). Predicting the wetland distributions under climate warming in the Great Xing’an Mountains, northeastern China. Ecological Research, 26(3), 605–613. http://dx.doi.org/10.1007/s11284-011-0819-2.
Mahdianpari, M., Salehi, B., Mohammadimanesh, F., Homayouni, S., & Gill, E. (2019). The First Wetland Inventory Map of Newfoundland at a Spatial Resolution of 10 m Using Sentinel-1 and Sentinel-2 Data on the Google Earth Engine Cloud Computing Platform. Remote Sensing, 11(1), 43. https://doi.org/10.3390/rs11010043.
Merchant, M. A., Warren, R. K., Edwards, R., & Kenyon, J. K. (2019). An Object-Based Assessment of Multi-Wavelength SAR, Optical Imagery and Topographical Datasets for Operational Wetland Mapping in Boreal Yukon, Canada. Canadian Journal of Remote Sensing, 45(3–4), 308–332. https://doi.org/10.1080/07038992.2019.1605500.
Millard, K., & Richardson, M. (2013). Wetland mapping with LiDAR derivatives, SAR polarimetric decompositions, and LiDAR–SAR fusion using a random forest classifier. Canadian Journal of Remote Sensing, 39(4), 290–307.
Ozesmi, S. L., & Bauer, M. E. (2002). Satellite remote sensing of wetlands. Wetlands Ecology and Management, 10(5), 381–402. https://doi.org/10.1023/A:1020908432489.
Leave a Reply