Summary
In this post, I use cross-validated climate year classifications to compare the effectiveness of linear discriminant analysis (LDA) vs. nearest neighbour classification on spatiotemporally standardized principal components (ST PCA). Despite achieving lower correct classification rates on training data, ST PCA performed as well as LDA on test data. This supports theoretical reasoning that ST PCA should be less prone than LDA to overfitting due to the structure of its eigenspace. Neither method showed evidence of overfitting at high dimensions, a perplexing result that deserves further consideration. These results suggest that the benefits of ST PCA over LDA—i.e. a more logical climate space for climate change analysis—do not come at the cost of lower classification effectiveness.
Introduction
In previous posts, I developed the methodology of spatiotemporal standardization (STS) as a way of structuring the climate space of British Columbia around historical variability and the differences between BEC variants. Doing STS on the raw data, and again on truncated principal components creates a climate space in which nearest-neighbour classification is similar to classification via linear discriminant analysis (LDA). Nevertheless, I found that LDA was somewhat more effective at climate year classification in training data, and thus possibly more desirable for classification of future climates. The purpose of this post is to do a first pass on cross-validated comparison of LDA and what for the moment I am calling spatiotemporal principal components analysis (ST PCA).
Classification Methods
The data for this analysis is a 1961-1990 time series of 14 annual variables at each of 168 BEC variant centroid surrogates. This is data from ClimateWNA v4.72.
Both methods use nearest-neighbour classification (k=1). Each 14-variable climate year is classified by assigning it to the nearest BEC variant 30-yr normal. The only difference between the two methods is the eigenspace in which this Euclidian measure is performed.
The eigenspace for the LDA is calculated using the “lda” call in the MASS package of R. This call extracts eigenvectors based on the ratio of between-group to within-group scatter, then standardizes the eigenvectors to unit within-group variance. I have confirmed that nearest neighbour classification in this eigenspace produces identical results to the classification produced by the predict(lda) call.
The eigenspace for the ST PCA is created by the following process: (1) standardizing the 14 raw climate variables by the average standard deviation of temporal variability of each BEC variant; (2) PCA using the “prcomp” call in the MASS package of R; and (3) standardizing retained eigenvectors by the average standard deviation of temporal variability of each BEC variant. The first round of standardization has the effect of supervising the PCA so that it selects eigenvectors with a high ratio of spatial (between-group) to temporal (within-group) variation. The second round of standardization removes the influence of redundant and correlated variation in the raw data, and appears to be similar to the eigenvector standardization performed by the “lda” call.
Cross-validation methodology
Two measures are taken to reduce the influence of spatial and temporal autocorrelation on the cross-validation results, using the “xval.buffer” method of the CaDENCE package in R (Cannon 2012). First, spatial autocorrelation is addressed by testing against blocks of the same three contiguous years in all BEC variants. Second, serial autocorrelation is addressed by a three-year buffer on the test data: i.e. 3 years on either side of the test data are withheld from the training data. There are 10 iterations of cross-validation over the 30-yr classification period, as illustrated in Figure 1.
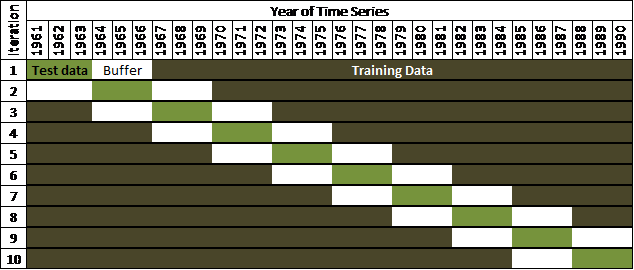
Figure 1: illustration of buffered cross-validation using test data composed of contiguous blocks of three years, using the “xval.buffer” method of the CaDENCE package in R (Cannon 2012).
The meaning of “correct” in climate year classification
Supervised classification methods such as LDA are based on the principle of training the classification model with data of known class, and validating the model with test data of known class. In this typical context, the skill of the model is inferred from “correct classification rate”: the proportion of the test observations that are assigned the correct known class. In the context of climate year classification, there is no true “correct” classification: the a priori class of each climate year is the spatial location of the observation (e.g. BEC variant centroid surrogate), and the assigned class is the climatic condition (e.g. 30-yr normal) that the climate year most closely resembles. “correct classification rate” in this context depends both on the ability of the model to differentiate the groups, and on the intrinsic differention (degree of overlap) between the groups. For this reason, “differentiation” is a more precise term for correct classification rate in climate year classification.
Results
As demonstrated in previous posts, LDA achieves higher differentiation in the training data than ST PCA (Figure 2). However, both methods achieved similar differentiation in the test data, suggesting that ST PCA and LDA are equally effective as climate year classification methods. Overfitting due to dimensionality is not apparent: differentiation in the test data declined only very slightly when more than ten eigenvectors were retained for classification. Cross-validated differentiation of individual BEC variants is equivalent for both methods (Figure 3).
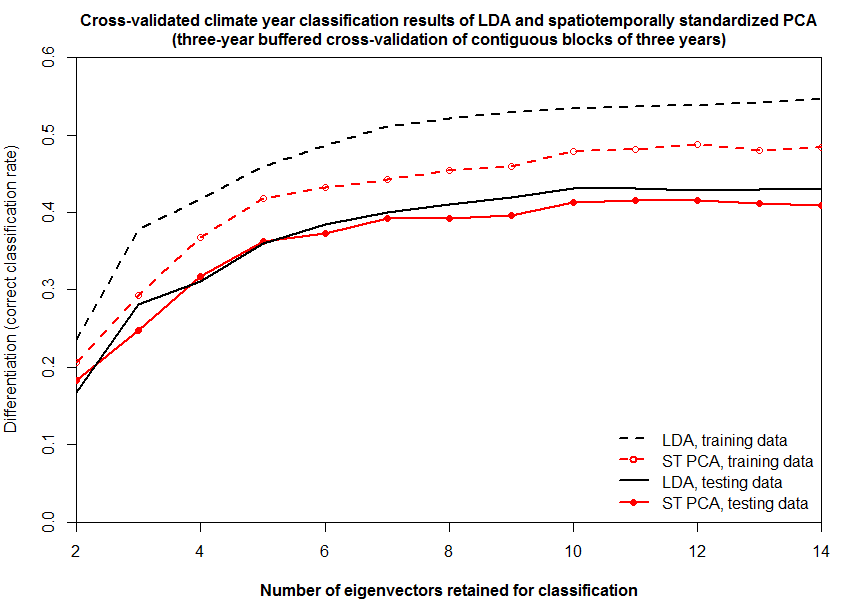
Figure 2: cross-validated climate-year differentiation skill of LDA and ST PCA, for increasing dimensionality of eigenspaces.
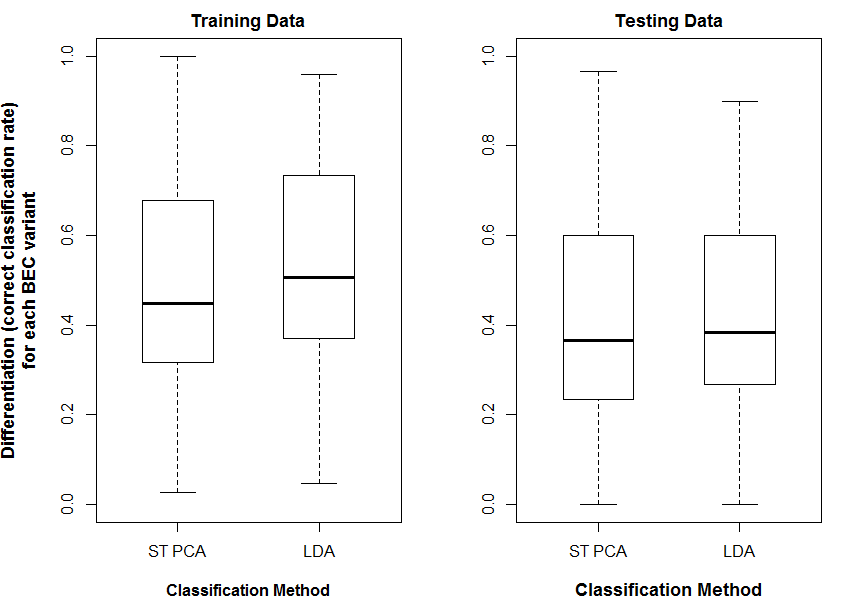
Figure 3: cross-validated climate-year differentiation skill of LDA and ST PCA, showing the distribution of differentiation rates for each of the 168 BEC variants. Both classifications used 10 eigenvectors.
Discussion
Prior to this analysis, I expected LDA to be more prone to overfitting because selecting eigenvectors based purely on the ratio of between-group to within-group variance allows eigenvectors with low variance to be assigned moderate rank. ST PCA is likely more robust to overfitting because it prioritizes between-group variation while still ranking eigenvectors based on variance. This analysis suggests that LDA is indeed more prone to overfitting than ST PCA. The extent of overfitting in LDA was such that both methods have equivalent differentiation skill on the test data, despite better differentiation by LDA on the training data. This suggests that the other advantages of ST PCA over LDA, e.g. its more logical eigenvector structure, do not come at a cost in terms of classification skill.
The lack of overfitting at high dimensions is perplexing. I expected to see a dramatic decline in cross-validated skill of both methods when more than 10 eigenvectors were retained. Both methods standardize the retained eigenvectors to unit within-group variance. The effect of this standardization is to make all retained eigenvectors the same importance in the classification. It would seem logical that inflating the variance of dimensions with no discriminating power would confound the distance metric used for classification. I would also expect that the addition of these trivial dimensions would begin to invoke the curse of dimensionality, in which all observations seem equally distant from any given point in high-dimensional space. Neither of these effects are apparent, and the failure of this logic warrants further consideration.
Independent test data are essential for reliable model validation. This is problematic for climate year classification, since the cross-validated skill of classification models is inflated by serial autocorrelation of time series data (Shabbar and Kharin 2007). The problem of finding independent data is exacerbated by the fact that there is no a priori class of a climate year, and thus no definitive means of declaring a classification as “correct”. However, the objective of this analysis is to compare the differentiating skill of LDA and spatiotemporal PCA, rather than to assess the absolute skill of either method. Imperfectly independent test data are likely to be adequate to assess the relative effectiveness of the methods.
References
Cannon, A. J. 2012. Neural networks for probabilistic environmental prediction: Conditional Density Estimation Network Creation & Evaluation (CaDENCE) in R. Computers & Geosciences 41:126–135.
Shabbar, A., and V. Kharin. 2007. An assessment of cross-validation for estimating skill of empirical seasonal forecasts using a global coupled model simulation. CLIVAR Exchanges 12:10–12.