This is an oldie, but a goodie…here is what the table looks like, but you need to click on the link to get the full effect.

And, a link to reviews of tools for data visualization.
constructing a good life through the exploration of value and valuing
This is an oldie, but a goodie…here is what the table looks like, but you need to click on the link to get the full effect.
And, a link to reviews of tools for data visualization.
While the distinction between formative and summative evaluation is often drawn too sharply, there is a real distinction. For formative evaluation to really be formative, there needs to be a steady flow of evaluative feedback that allows for corrections along the way… that is, to do what ever is being done better, both in the present and into the future.
Compare two approaches to formative evaluation ~ real time evaluation and digital portfolios of student learning.
Real Time Evaluation

http://reliefweb.int/report/nepal/nepal-gorkha-earthquake-2015-internal-real-time-evaluation-emergency-health-response
An evaluation approach that captures this is “real time evaluation,” an idea that appears often in humanitarian relief efforts. With a disastrous situation that demands rapid alleviation of suffering comes the need for quick information about whether that suffering is indeed being alleviated, and if it isn’t then what might be done in order to do so. RTE emphasizes timely evaluation feedback to strengthen program design and implementation, some common features are:
Digital Portfolios of Student Learning
While traditional report cards have long been the mainstay in reporting student learning technology that allows for ongoing feedback about what and how students are learning are now common. Digital portfolios are collections of evidence managed by users and shared electronically, often on the web but increasingly through other social media platforms. One example is Fresh Grade, an app that facilitates documenting and sharing learning activities and outcomes. Common features of digital portfolios are:
What can we learn from these examples?
RTE is often done under difficult circumstances with limited ability to collect data first hand and thus is content with ‘quick and dirty’ results. Disaster situations make it onerous to be in the field and evaluation relies on reports from the field (observations of aid workers, sector staff in the area, and so on). On the other hand, classrooms and other educational settings are easy to access, but the data about learning activities and outcomes are similar to reports from the field. Digital portfolios and especially the real time apps (like Fresh Grade) provide immediate evidence of what is going on and what is being accomplished. Apps allow students and teachers to create and share information on an ongoing basis, but permit editing and adding to the record over time. If we think about an individual student’s learning as a model for a program, perhaps this technology has something to offer formative program evaluation.
RTE could use an app or web based platform (most are available for smart phones and tablets, and there are a number of web-based tools that might serve this purpose: Evernote, Google drive, Three Ring) so those on the ground could provide data about what is happening by sending photographs, interviews, observations, documents, and so on to evaluators who are unable to collect data firsthand. Connectivity may be an issue in some situations, but even erratic connection would allow for varied and compelling data to be shared. In non-emergency situations this wouldn’t be a problem. Technology that allows for sharing information easily and often may increase the likelihood adjustments can be made and thus the purpose of formative evaluation realized.
 In educational evaluation the global educational reform movement (GERM) has privileged common indicators of student learning outcomes (used in turn for other evaluation purposes like teacher evaluation, even if not a sound practice). There are many reasons why standardized tests become the norm and are reified as the only fair and legitimate way to know how students and schools are doing. There is plenty of literature that debunks that idea.
In educational evaluation the global educational reform movement (GERM) has privileged common indicators of student learning outcomes (used in turn for other evaluation purposes like teacher evaluation, even if not a sound practice). There are many reasons why standardized tests become the norm and are reified as the only fair and legitimate way to know how students and schools are doing. There is plenty of literature that debunks that idea.
However, the narrative of standardized testing as a necessary and legitimate means of judging the quality of learning and schooling is powerful and political. In a short commentary for NPR a reporter, Anya Kamenetz, nicely summarizes reasonable alternatives, and these are excellent talking points when confronted with the question, “If not standardized tests, what then?” You can read the article, but in summary:
1) use some sort of matrix sampling (a good idea from NAEP)
2) consider ongoing embedded assessments (this is usually computer based testing)
3) think about what you want to know and it will require multiple measures (in other words, knowing scores in a few subject areas will never be enough, and maybe there are things worth knowing beyond the obvious)
4) start considering novel approaches to assessment, like game based assessment and the not so novel use of portfolios or narrative evaluations
5) think differently about what it means to judge a school and that means looking at more than just narrow student outcomes (school inspections are a notion worth revisiting).
Logic models (similar to program theory) are popular in evaluation. The presumption is that programs or interventions can be depicted in a linear input output schema, simplistically depicted as:
![]()
This simple example can be illustrated by using this model to evaluate how an information fair on reproductive health contributes to the prevention of unwanted pregnancies.
The inputs are the money, labour, and facilities needed to produce the information fair.
The activity is organizing and presenting the information fair.
The output is that some people attend the info fair.
The outcome is that some of those who attend the info act on the information provided.
The impact is that unwanted pregnancies are reduced.The idea is that each step in this causal chain can be evaluated.Did the inputs (money etc.) really produce the intervention?
And did the activities produce the output (an informed audience)?
Did the output produce the outcome (how many attendees acted on the information)?
To measure the impacts, public health statistics could be used.
A quick overview of logic models is provided on the Audience Dialogue website. One of the best online resources for developing and using logic models is Kellogg Foundation’s Logic Model Development Guide, and loads of visual images of logic models are available, and aboriginal logic models have also been developed.
See also Usable Knowledge’s short tutorial on creating a logic model.
And readIan David Moss’ In Defense of Logic Models, which is probably the most reasoned response to many of the criticisms… take a look at the comments to his blog post as they extend the discussion nicely.
 Doctors, forensic scientists, and police officers have been early adopters of Google Glass as a way of collecting data, of recording events that matter to their professional practice. This recording device is double edged: on the one hand they make the transmission of surveillance data incredible easy (maybe too easy), but on the other hand the data might be used to evaluate the performance of the surgeon, physician or police officer wearing them. So personnel evaluation might evolve with a data record of actual performance ~ you can see the quality of the surgery performed or the propriety of an arrest.
Doctors, forensic scientists, and police officers have been early adopters of Google Glass as a way of collecting data, of recording events that matter to their professional practice. This recording device is double edged: on the one hand they make the transmission of surveillance data incredible easy (maybe too easy), but on the other hand the data might be used to evaluate the performance of the surgeon, physician or police officer wearing them. So personnel evaluation might evolve with a data record of actual performance ~ you can see the quality of the surgery performed or the propriety of an arrest.
Some evaluators spend considerable time in programmatic contexts collecting observational data. One wonders if recording devices that just come along with us and record what is going on might be useful for evaluators. For example, the GoPro, strapped to your head or chest, is now standard equipment for sports enthusiasts to capture their accomplishments or nature enthusiasts their surroundings. It might well be the means to record that program activity or meeting, but it might also be a bit intrusive.
Google Glass is definitely more stylish, less obtrusive, and provides interactive capabilities. It’s in the beta stage, what Google calls the Explorer Program and if a space is available you could be an early adopter for the cost $1500, that is if you live in the USA. In short you tell it what to do, take a picture or video, which you can share, send a message, look up information. The example below shows some of its capabilities. Imagine an evaluation context that would allow you to record what you see, do and to share and connect with program stakeholders.
Google Glass has been controversial when people wear them as a matter of course in their daily lives creating exaggerated tensions in an already surveillance rich society (smart phones being the obvious device). But used in an evaluation context, where people have accepted that events, interactions, and talk will be recorded, these controversies might be obviated.
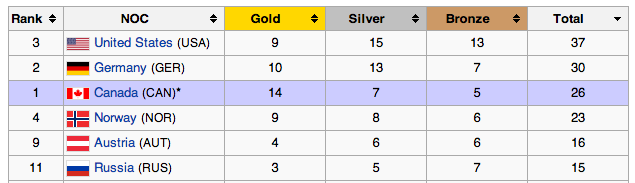
 Wherever in the world you were watching the Olympics from, there would have been a nationalistic bias in what you saw and a constant counting and recounting of medals to assert the superiority of your country over all others (you hope) or at least over some other countries. That Russia, the host country, earned the most medals, and especially the most gold and silver medals declares Russia simply as #1, best in the world, and highly accomplished in amateur sports. Russia is followed by the USA, Norway, Canada, and the Netherlands in terms of national prowess in winter sports.
Wherever in the world you were watching the Olympics from, there would have been a nationalistic bias in what you saw and a constant counting and recounting of medals to assert the superiority of your country over all others (you hope) or at least over some other countries. That Russia, the host country, earned the most medals, and especially the most gold and silver medals declares Russia simply as #1, best in the world, and highly accomplished in amateur sports. Russia is followed by the USA, Norway, Canada, and the Netherlands in terms of national prowess in winter sports.
This ranking is based on the number of medals received regardless of the level of medal. Naturally, it is the media that creates these rankings (not the IOC) and this rather simple strategy might distort who is the best (if this notion of the best has any construct validity, but that’s another discussion). It seems fairly obvious that getting the gold is better than getting the silver and that both trump getting a bronze medal. If we weighted the medal count (3 pts for gold, 2 for silver, and 1 for bronze) would the rankings of countries change? They do, a bit, and there are two noticeable changes. First is that Russia is WAY better than even the other top five ranking countries with a score of 70, compared to the next highest scoring country, Canada (which has moved from fourth to second place) with a score of 55. Perhaps less profound, but still an interesting difference is that although overall the USA had two more medals than Norway their weighted scores are identical at 53.
 But wait. The Olympics are held every four years and while one might expect relative stability in the rankings. The table to left is the top six ranked countries in 2010, when the Olympics were held in beautiful Vancouver, BC (no bias, on my part here). Russia squeaks into the top six ranked countries.
But wait. The Olympics are held every four years and while one might expect relative stability in the rankings. The table to left is the top six ranked countries in 2010, when the Olympics were held in beautiful Vancouver, BC (no bias, on my part here). Russia squeaks into the top six ranked countries.
So two things to note: 1) using the weighted scoring suggested above the order doesn’t change and we get a similar magnitude of performance [USA score = 70; Germany = 63; Canada = 61; Norway = 49; Austria = 30; Russia = 26], and 2) something miraculous happened in Russia in the last four years! Russia’s weighted score went from 26 in 2010 to 70 in 2014.
Looking across 2006, 2010, and 2014 you get a different picture with the countries that appear in the top six countries changing and the stability of the weighted ranking fluctuating notably.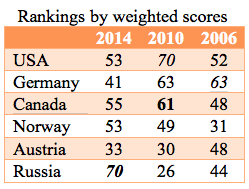 There are a couple of take away messages for evaluators. The simply one is to be cautious when using ranking. There are quite specific instances when evaluators might use ranking (textbook selection; admissions decisions; research proposal evaluation are examples) and a quick examination of how that ranking is done illustrates the need for thoughtfulness in creating algorithms. Michael Scriven and Jane Davidson offer an alternative, a qualitative wt & sum technique, to a numeric wt & sum strategy I have used here, and it is often a great improvement. When we rank things we can too easily confuse the rankings with grades, in other words, the thing that is ranked most highly is defined as good. In fact, it may or may not be good… it’s all relative. The most highly ranked thing isn’t necessarily a good thing.
There are a couple of take away messages for evaluators. The simply one is to be cautious when using ranking. There are quite specific instances when evaluators might use ranking (textbook selection; admissions decisions; research proposal evaluation are examples) and a quick examination of how that ranking is done illustrates the need for thoughtfulness in creating algorithms. Michael Scriven and Jane Davidson offer an alternative, a qualitative wt & sum technique, to a numeric wt & sum strategy I have used here, and it is often a great improvement. When we rank things we can too easily confuse the rankings with grades, in other words, the thing that is ranked most highly is defined as good. In fact, it may or may not be good… it’s all relative. The most highly ranked thing isn’t necessarily a good thing.
I introduced this series of posts by highlighting the evaluation of snowboarding… but there are multiple events within snowboarding and they do not all use the same evaluation strategy. While many of the specific events use a component evaluation strategy (separate judges looking at different parts of the athletes’ performance), the slope style event uses a holistic evaluation strategy, that is, each of six judges gives a grade from 1 – 100 considering a range of features of the run (including things like creativity, difficulty, execution of tricks, landings) but it is the overall impression that is the primary focus.

Yesterday’s first round of slopestyle boarding introduces us to a number of evaluation issues, but let’s focus on one: holistic scoring isn’t transparent and justifying the evaluative claim can be dodgy.
When top ranked Canadian slopestyler Mark McMorris received a score of 89.25 (which put him 7th) his response was: “It’s a judged sport; what can you do?” Canadian team coach Leo Addington repeated this perspective: “It’s a judged sport, and they saw what they saw and they put down what they thought.” He went on: “It’s always hard to tell without putting each run side by side, and the judging has many criteria – execution, amplitude, use of force, variety, progression. All those things are included in their thoughts … and they’re judging the entire run, completely, all those little things that sometimes we miss or don’t miss. It’s really hard to tell unless you study each one in slow motion all the way through.”
Holistic scoring is common in many evaluation contexts (assessments of student writing, lots of program evaluation) and expert judges (like teachers) assert they know a good performance when they see one without necessarily dissecting the performance. But it is more difficult to justify a holistic score and more difficult to challenge its veracity.
Coach Addington’s suggestion that judging each run in slow motion rather than as it is actually occurring is an interesting, although misguided, suggestion. Of course we see things differently in slow mo (that’s what the sports replay is all about) but that isn’t what is being judged in the case of most sports… what is being judged is the actual, authentic performance and even when replays show an error in judgement (let say about a penalty in hockey or a ball/strike in baseball) that judgement is mostly not overturned. So, the justification for a holistic score can’t be that you change the evaluand in order to make it clearer how you arrive at the judgement.
So how can holistic scoring be improved and justified? Slopestyle is a very recent “sport” and so the accumulation of collective expertise about what counts as a quality performance isn’t well formulated and one imagines that over time the quality of the judging will improve… there will be higher levels of agreement among judges and among judges, coaches and athletes. In fact, in the slopestyle instance, the coaches and judges do have relationships that provide for learning from each other. Again, quoting Coach Addington: “We [coaches and judges] can sit down and discuss and say, ‘What did you see, what did we see?’ Maybe we missed something, and we learn from it and that’s how it’s evolving. They learn our perspective and we learn their perspective.” While the media has mistakenly conjured up an image of fraternization between judges and coaches, they misunderstand that evaluations that are fair, transparent and justifiable are necessarily dependent on just such conversations. Holistic scoring approaches can only be better with the development of greater expertise through experience in knowing what that ideal type, the strong overall impression looks like.
NOTE: For the rest of the snowboarding world and media the real story in snowboarding has been US snowboarder Shaun White’s withdrawal from the slopestyle competition.
The Olympics are a rich learning opportunity. We can learn about global politics, “celebration capitalism”, gender identity, gender politics, fascism, to name just a few analytic frames for the Olympic Games. We can also learn a great deal about evaluation from the Olympics. While in graduate school I took an evaluation class with Terry Denny and we tried to understand educational evaluation by investigating how evaluation was done in other contexts. It was fun and instructive to consider how wine tasting, diamond grading, dog trials & shows, and yes judging sports might help us to think more carefully and creatively about evaluating educational programs.
So the Olympics give us a peek at how evaluation is done within many specific sports. And they aren’t all the same!
For example, judging snowboarding involves five judges grading each snowboarder’s run on a scale of .1 – 10, with deductions for specific errors. The judges have specific components of the snowboarder’s run to judge: one judge scores the standardized moves, another scores the height of maneuvers, one scores quality of rotations, and two score overall impression. There are bonus points for really high maneuvers… an additional point is given for every additional 30 centimeters the competitor reaches above the lip of the pipe.
Falls and other mistakes lead to deductions. The format for point deduction in halfpipe is as follows:
0.1–0.4 for an unstable body, flat landing, or missed airs
0.5–0.9 for using hand for stability
1.0–1.5 for minor falls or body contact with the snow
1.6–1.9 for complete falls
2.0 for a complete stop
Note that this is not the same system used in judging all snowboarding… the World Snowboard Tour uses a different system.
So over the next couple of weeks I’ll be posting about what evaluation practitioners and theorists might possibly learn from the judging fest in Sochi.

Available in April, a new edited book (Guilford Press) that explores the ‘whats,’ ‘whys,’ and ‘hows’ of integrating feminist theory and methods into applied research and evaluation practice.
CONTENTS
I. Feminist Theory, Research and Evaluation
1. Feminist Theory: Its Domain and Applications, Sharon Brisolara
2. Research and Evaluation: Intersections and Divergence, Sandra Mathison
3. Researcher/Evaluator Roles and Social Justice, Elizabeth Whitmore
4. A Transformative Feminist Stance: Inclusion of Multiple Dimensions of Diversity with Gender, Donna M. Mertens
5. Feminist Evaluation for Nonfeminists, Donna Podems
II. Feminist Evaluation in Practice
6. An Explication of Evaluator Values: Framing Matters, Kathryn Sielbeck-Mathes and Rebecca Selove
7. Fostering Democracy in Angola: A Feminist-Ecological Model for Evaluation, Tristi Nichols
8. Feminist Evaluation in South Asia: Building Bridges of Theory and Practice, Katherine Hay
9. Feminist Evaluation in Latin American Contexts, Silvia Salinas Mulder and Fabiola Amariles
III. Feminist Research in Practice
10. Feminist Research and School-Based Health Care: A Three-Country Comparison, Denise Seigart
11. Feminist Research Approaches to Empowerment in Syria, Alessandra Galié
12. Feminist Research Approaches to Studying Sub-Saharan Traditional Midwives, Elaine Dietsch
Final Reflection. Feminist Social Inquiry: Relevance, Relationships, and Responsibility, Jennifer C. Greene
Outcome Harvesting is an evaluation approach developed by Ricardo Wilson-Grau. Using a forensics approach, outcome harvesting has the evaluator or ‘harvester’ retrospectively glean information from reports, personal interviews, and other sources to document how a given program, project, organization or initiative has contributed to outcomes.  Unlike so many evaluation approaches that begin with stated outcomes or objectives, this approach looks for evidence of outcomes, and explanations for those outcomes, in what has already happened… a process the creators call ‘sleuthing.’
Unlike so many evaluation approaches that begin with stated outcomes or objectives, this approach looks for evidence of outcomes, and explanations for those outcomes, in what has already happened… a process the creators call ‘sleuthing.’
This approach blends together, and maybe eliminates the distinctions, among intended and unintended outcomes. Evaluators are enjoined to look beyond what programs say they will do to what they actually do, but in an objectives driven world this requires evaluators to convince clients that this is important or necessary, and justifying the expenditure of evaluation resources on a broader concept of outcomes than is often defined.
Wilson-Grau has written a clear explanation of the process, which can be downloaded here. In the downloadable pdf, the six steps of outcome harvesting are summarized:
1. Design the Outcome Harvest: Harvest users and harvesters identify useable questions to guide the harvest. Both users and harvesters agree on what information is to be collected and included in the outcome description as well as on the changes in the social actors and how the change agent influenced them.
2. Gather data and draft outcome descriptions: Harvesters glean information about changes that have occurred in social actors and how the change agent contributed to these changes. Information about outcomes may be found in documents or collected through interviews, surveys, and other sources. The harvesters write preliminary outcome descriptions with questions for review and clarification by the change agent.
3. Engage change agents in formulating outcome descriptions: Harvesters engage directly with change agents to review the draft outcome descriptions, identify and formulate additional outcomes, and classify all outcomes. Change agents often consult with well- informed individuals (inside or outside their organization) who can provide information about outcomes.
4. Substantiate: Harvesters obtain the views of independent individuals knowledgeable about the outcome(s) and how they were achieved; this validates and enhances the credibility of the findings.
5. Analyze and interpret: Harvesters organize outcome descriptions through a database in order to make sense of them, analyze and interpret the data, and provide evidence-based answers to the useable harvesting questions.
6. Support use of findings: Drawing on the evidence-based, actionable answers to the useable questions, harvesters propose points for discussion to harvest users, including how the users might make use of findings. The harvesters also wrap up their contribution by accompanying or facilitating the discussion amongst harvest users.
Other evaluation approaches (like the Most Significant Change technique or the Success Case Method) also look retrospectively at what happened and seek to analyze who, why and how change occurred, but this is a good addition to the evaluation literature. An example of outcome harvesting is described on the BetterEvaluation Blog. A short video introduces the example. watch?v=lNhIzzpGakE&feature=youtu.be