In the run up to the Academy Awards I was catching up on nominated movies. This past weekend I saw several including The Big Short. A Salon review summarizes the all to familiar story of the movie:
A Salon review summarizes the all to familiar story of the movie:
In the late 1990s, banks and private mortgage lenders began pushing subprime mortgages, many with “adjustable” rates that jumped sharply after a few years. These risky loans comprised 8.6 percent of all mortgages in 2001, soaring to 20.1 percent by 2006. That year alone, 10 lenders accounted for 56 percent of all subprime loans, totaling $362 billion. As the film explains, these loans were a ticking time bomb, waiting to explode.
While there is really nothing new revealed in the movie, there is a great scene in which Mark Baum (Steve Carrell) confronts the Standard and Poor’s staffer who admits to giving high ratings to mortgage security bonds because the banks pay for the ratings. If S&P doesn’t deliver the high ratings, the banks will take their business elsewhere, perhaps to Moody’s. The profit incentive to be uncritical, to not evaluate, is overwhelming. Without admitting any wrong doing it has taken until 2015 for S&P (whose parent company is MacGraw Hill Financials) to make reparations in a $1.4M settlement with the US Justice Department.
 This is a particular and poignant message for evaluation and evaluators. Like so much else about the financial crisis, shortsightedness and greed resulted in false evaluations, ones with very serious consequences. S&P lied: they claimed to be making independent evaluations of the value of mortgage backed securities, and the lie meant making a larger than usual profit and facilitating banks’ bogus instruments. Moody did the same thing. While the ratings agencies have made some minor changes in their evaluation procedures the key features, lack of independence and the interconnection of their profit margin with that of their customers, have not. The consensus seems to be there is nothing that would preclude the evaluators from playing precisely the same role in the future.
This is a particular and poignant message for evaluation and evaluators. Like so much else about the financial crisis, shortsightedness and greed resulted in false evaluations, ones with very serious consequences. S&P lied: they claimed to be making independent evaluations of the value of mortgage backed securities, and the lie meant making a larger than usual profit and facilitating banks’ bogus instruments. Moody did the same thing. While the ratings agencies have made some minor changes in their evaluation procedures the key features, lack of independence and the interconnection of their profit margin with that of their customers, have not. The consensus seems to be there is nothing that would preclude the evaluators from playing precisely the same role in the future.
In addition, while the ratings companies profits took a serious hit the big three agencies—Moody’s, S&P and Fitch— their revenues surpassed pre-crisis levels, and Moody’s and S&P now look more attractive as businesses than most other financial firms do. Something worth pondering another day.
 Individual evaluators may say, “Well, I wouldn’t do that” and that may be to some extent true, but the same underlying relationships are repeated in all contracted evaluation work. If you are hiring me to do evaluation for you and I want you to consider hiring me again in the future then I am in the same relationship as the ratings agencies are to financial institutions. This is a structural deficiency, and a serious one. In a soon to be published book chapter (in Evaluation for an Equitable Society), I analyze how capitalism has overwhelmed pretty much everything. We are unable to see a role for evaluation theory and practice outside the fee-for-service framework dictated in the current neoliberal frames of social engagement.
Individual evaluators may say, “Well, I wouldn’t do that” and that may be to some extent true, but the same underlying relationships are repeated in all contracted evaluation work. If you are hiring me to do evaluation for you and I want you to consider hiring me again in the future then I am in the same relationship as the ratings agencies are to financial institutions. This is a structural deficiency, and a serious one. In a soon to be published book chapter (in Evaluation for an Equitable Society), I analyze how capitalism has overwhelmed pretty much everything. We are unable to see a role for evaluation theory and practice outside the fee-for-service framework dictated in the current neoliberal frames of social engagement.
In that chapter I offer suggestions about what evaluation can do, alongside being more responsible within a fee for service framework. First, evaluation needs to evaluate its own systems and instruments. Meta-analysis of evaluations (like that done by S&P, and pharmaceutical companies, by grant funding agencies, in education, and so on) are necessary. Using our skills to insure that what is being done in the name of evaluation is indeed evaluative and not merely profiteering is critically important. Second, professional evaluation associations need to promote structures for truly independent evaluations, evaluations solicited and paid for by third parties that have no profit to make although, of course, an interest (government agencies, funding agencies, and so on) in competently done, valid evaluation studies.
 In September I was honoured to give the initial keynote address at the 2017 Australasian Evaluation Society meeting in Canberra. I am thankful for the opportunity and for the warm response my keynote received.
In September I was honoured to give the initial keynote address at the 2017 Australasian Evaluation Society meeting in Canberra. I am thankful for the opportunity and for the warm response my keynote received. Follow
Follow








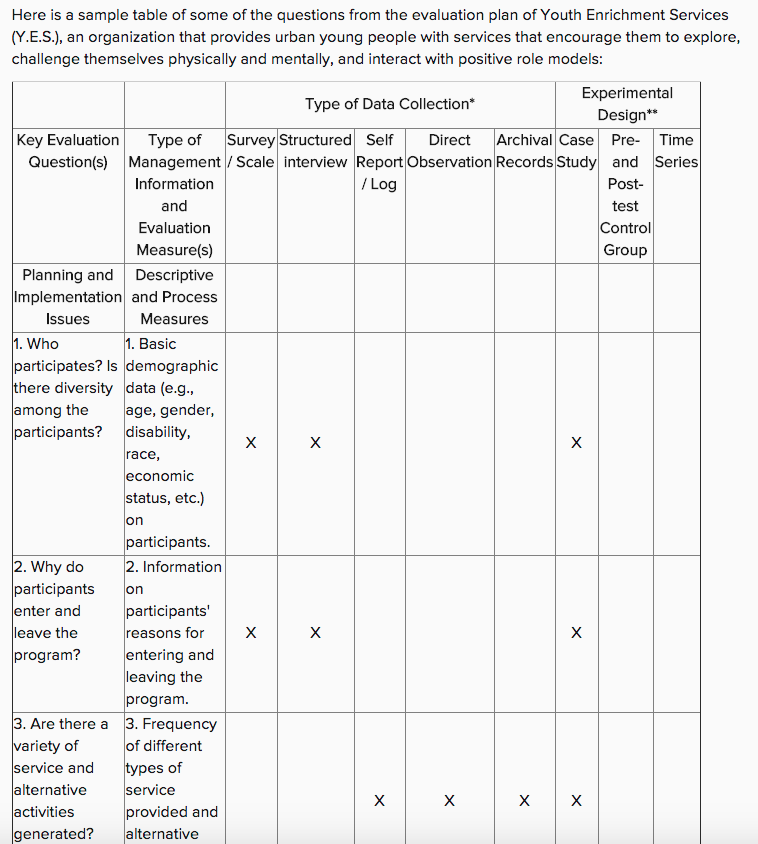
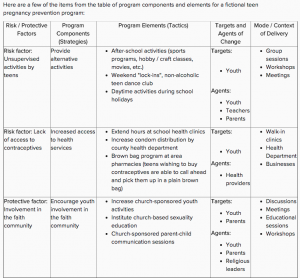 For example, describing the program and what it is supposed to accomplish might look like this.
For example, describing the program and what it is supposed to accomplish might look like this.