Error, uncertainty, accuracy and precision are very important concepts in GIScience, but the issues associated with them are often overlooked. This becomes very apparent when you discuss GISystems with the typical GIS user. The idea that there is uncertainty present in the data that could influence analysis outcomes– a result of the error and uncertainty in the source data and introduced by the processing of that data–is often mentioned only in passing in official reports. However, the issues that arise from uncertainty–error, accuracy and precision– are very important. The quality of the decisions that can be made, based on any set of data, depend to a large extent upon the quality of the information that was used to make those decisions. This situation is not unique to GIScience, of course, but is highlighted when spatial data are collected, analyses conducted, and spatial output created. Since it is relatively easy to combine data from a wide range of sources, GIS analyses and presentations (e.g., a map) will often bring to light the poor quality of the information that people have been using over the years.
In order to know whether data are appropriate for an analysis, it is important to look at its metadata (data about data). Using metadata you can reduce the error and uncertainty in your analyses, since you’ll know about the source of the data, what modifications have been made to the data, etc.
When overlaying two layers obtained from different agencies you often end up with a situation such as that illustrated below (Question: are the polygon boundaries supposed to line up, or do they reflect actual differences in the soil types / land use polygons?):
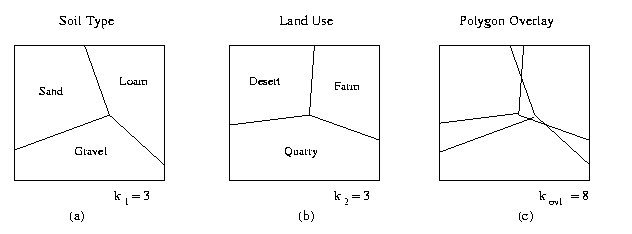
The differences between the polygon boundaries are referred to as slivers:
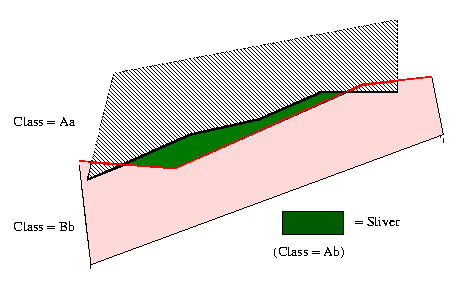
The questions you need to ask–are the differences meaningful or simply the result of uncertainties associated with data collection (possibly collected at different dates, at different scales) and/or generalization (mandate issues)? What set of polygon boundaries should you accept as ‘real’, and which should you reject? Or, should you take the average of the two sets of polygons? Most often answers to these questions are left up to the person doing the work, since there are no formal guidelines available.
Learning Objectives
- Understand the concept of uncertainty and how it can arise from our attempts to represent reality.
- Be aware of how uncertainty is introduced as we conceptualize, measure, represent and analyze spatial data;
- Understand how and why scale affects measurements and analyses;
- Understand the importance of metadata.
Recommended Readings
Slides from the lecture are on Canvas.
Text: Chapter 5: Uncertainty
Alternative text: GIS Basics: Chapter 3.2
Recommended Readings
Top 10 Metadata Errors - by explaining what the common errors are, you get to know what the purpose of metadata is
Land Evaluation: Risk Uncertainty by David G. Rossiter - A very good overview of uncertainty, although the math is beyond what is required in this course.
For a thorough overview of the subject:
The Error Component in Spatial Data - Chapter 12 from the “Big Book”: of GIS by N.R. Chrisman
Useful Resources
Units, Significant Figures, Accuracy and Precision
Digital Elevation Model (DEM) Uncertainty: Evaluation and Effect on Topographic Parameters
BC Standards – entire set of standards that describes both attribute and spatial data and metadata standards
Time is often a forgotten dimension when considering datums. Here is a very interesting presentation on the differences between NAD83 and WGS84. (Relates to Georeferencing lecture.)
FGDC – What are Metadata?
Wikipedia: Standard Deviation
USGS: National Geospatial Program Standards (NGPS) Standards and Specifications.
Confusion Matrix: How can I assess my results?
General Sampling Considerations
Keywords
error, uncertainty, accuracy, bias, metadata, sliver polygons, NMAS (National Map Accuracy Standards), attribute accuracy