It often happens that you want to combine information from one data frame with information from another data frame. This can look a few different ways.
1. Adding rows
If the two data frames contain exactly the same variables, you can use the command rbind (row-bind).
result<-rbind(df1, df2)
Note that the variables don’t have to be in the same order!
2. Adding columns
If the two data frames contain exactly the same number of rows, and if you’re sure that the information will end up being appropriately matched row-by-row (for example if the second data frame contains only constants), you can use the cbind (column-bind) command.
result<-cbind(df1, df2)
However, usually you need some way of making sure that the new columns are matched with the correct rows. Consider trying to combine the following tables:
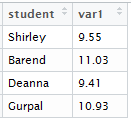
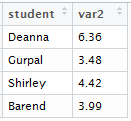
(Note that the numbers were generated using rnorm, one of R’s random number generating commands!) There are the same number of rows, but if you tried to use cbind you’d end up with Shirley’s information combined with Deanna’s. It would be possible to sort so that the tables were organized by alphabetical order of student name, but it’s much easier and safer to use the merge command. The basic command is simple:
result<-merge(df1, df2, by="student")
but in this case you could actually omit the “by” instruction: by default, merge looks to see whether there are any columns in the two data frames with the same name and uses that column (or those columns!) as the key.
The result of this command is
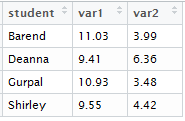
This approach is smart if you have a 1-to-1 matching of information in your two tables, but it’s essential if the matching isn’t 1-to-1. What if you wanted to merge the first table above with the following?
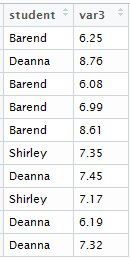
Using the same merge command, result<-merge(df1, df2), you arrive at the following:
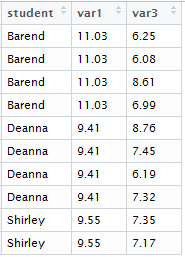
You see here that what merge does by default is form all valid combinations of the information from the two tables, where the ID variable matches. So because Barend appeared 4 times in the table with var3, he appears 4 times in this table, and the same value for var1 is copied each time; because Gurpal doesn’t appear in the table with var3, he doesn’t appear in this result table. You can control this behaviour by setting the option “all”: you can choose to keep all values from just one of the tables, or from both. Let’s try keeping both. Here’s the command:
result<-merge(df1, df2, all=TRUE)
and here’s the result:
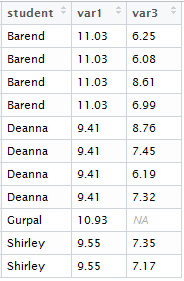
Because Gurpal has no value for var3, his value for var1 is reported and an NA is given for var3.