Blog Update #7: Final Recommendations & Reflection
a. Final conclusions and recommendations
Overall, our initial studies suggest that a family archiving system would be a valuable interface for future use. However, based on the results of our experiment, it is evident that further analysis must be done before continuing on any design changes as the experiment showed no difference between the two alternatives and we are not confident that we can truly accept the null hypothesis. Although Design B appears to be faster (based on mean calculation) and preferred by users, initial calculations also show it is more error prone than Design A. We take this observation with caution since our experiment did not conclude definitively that there was a difference. Due to these initial findings, we believe that our hypothesis might still be supported with a larger participant pool. Additionally, this suggests that a family tree representation we initially thought to be too complicated, might also be a valuable area of study especially when considering participant feedback wherein hierarchy and structure are given importance.
That said, we recommend also focusing the analysis on other aspects of the interface such as the timeline representation for events, which we were not able to do during the course of this experiment. We also feel that changing the appearance and layout design of the interface based on some valuable feedback from the questionnaire to avoid similar errors before performing further analysis.
b. Reflection on your design and evaluation process
We found that user involvement significantly changed the focus of our interface. Initially, we included lineage in the concept of our application but based on our field study, we felt that it would be beneficial to focus more on sharing and storing archives. Focusing on the representation of the family relations for our design experiment was a direct result of this finding. We felt that to properly support sharing of family archives, we also need to properly represent their relationships.
Interestingly enough, we found no difference between our two design alternatives, which we feel is due to the resource limitation of the experiment (e.g. time, the number of participants.) That said, we were still surprised to find Design B appears to be more error prone than Design A based on initial calculations. However, this might also be due to some appearance and layout issue that participants pointed out during the experiment. Despite these challenges, we feel that using HTML/PHP for our prototype was the best way to create our prototype.
Our evaluation process could have been improved by coming up with more stable metrics to determine what constituted valid user errors. We also could have made more tasks that involved more user decision making to create a much clearer distinction between the two interfaces. Perhaps it would be a good idea to see if maybe users would prefer to do their own graphical representation of family relations on just be able to link specific nodes of their representation to other users to which they are related. There is a lot of ground to cover in this largely untapped section of social media.
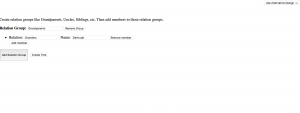
Our design was pretty simplistic, though that was mostly due to a skill deficit than anything else. The idea itself is nice in theory (i.e. give users the flexibility to define their own relations and relational groups such as grandma and grandparent respectively), but the execution proved to be much more difficult with all its moving parts and laborious data entry. Keep in mind that a lot of archiving is fairly laborious so it would be good to have some sort of minimization on the task of data entry. Our design gave some defaults to prompt users to think about certain relations and how they might fit family members into those customizable constructs, but it largely relied on the cognitive ability of a user to remember all their family ties. Maybe it would have been better to streamline it by making a user take a survey that clearly lays out to what extent they know their family and then only prompts them to enter data about members they know they have and edit them later if necessary.
Overall there were some failings in the design that we notice now, but the design served the purpose it needed to which was to get closer to a good consensus on how users like to represent their families.