
 Follow
FollowI was recently (kindly) invited by the Canadian Study of Parliament Group to talk about electoral systems and electoral reform. Here’s what I contributed. A bit pessimistic, perhaps, but mainly just a review of some literature on representation, accountability, and electoral systems.
INTRODUCTION
Ideally, government is representative and accountable, representative in the sense that its policies align with citizens’ interests, and accountable in the sense that it is answerable to citizens for its conduct and responsive to their demands. The electoral system plays an important role in determining how representative and accountable a government is in practice. Yet, it is tremendously difficult to identify an optimal electoral system, that is, one that maximizes both representation and accountability. This is because much research shows that electoral systems that advance representation tend to do so at the expense of accountability, and vice versa (Horowitz 2003).
The trade-off between accountability and representation is often portrayed as a fundamental obstacle to identifying an optimal electoral system, but any such trade-off is not really what prevents us from identifying an optimal electoral system. It is rather that we can neither i) reliably identify more or less representative electoral outcomes, nor ii) rely on repeated elections to hold incumbents to account.
THE REPRESENTATION-ACCOUNTABILITY TRADE-OFF
Representation
One can appreciate the effect of the electoral system on representation by recalling Downs’s (1957) model of electoral competition. The two parties in Downs’s model appeal to voters by altering their policy positions. The well-known result of the model is that both parties converge on the position of the median voter, who then randomly supports one of the parties to give it a majority. If we take as a metric of representation the policy distance between the median voter and the median legislator (this is called congruence), the result is perfectly representative.
Few real-world elections feature exactly two parties, and once more than two parties inhabit Downs’s model one or more of the parties may benefit by diverging from the median voter. This has less to do with the electoral formula (plurality or proportional representation (PR)) than the district magnitude (Cox 1990). Even so, Figures 1a and 1b convey how parties tend to arrange themselves under plurality or PR, respectively (see, e.g., Powell 2000). In Figure 1a, C takes up a position to the right of the median voter in the hope that A and B will split the vote to the left of the median voter so that C can secure a plurality of votes on the right. In Figure 1b, A, B and C distribute themselves evenly about the median voter’s position.
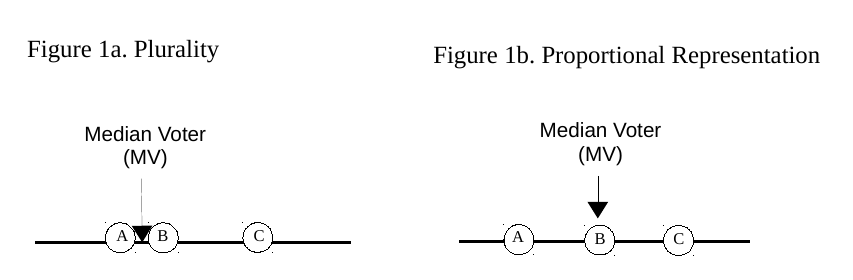
The representational consequences of these two stylized elections are quite different. If C were to win the plurality election in Figure 1a, there would be a substantial gap between the median voter and the majority party, C. There is no outright winner in PR elections, and in theory A, B, and C ought to arrange themselves in Figure 1b such that each obtains an equal share of the vote (else each would have cause to adopt a somewhat different position). This would result in legislature in which A, B and C have equal seat shares, and in which the median party (B) is therefore located exactly at the median voter’s position. In terms of congruence, the PR result is highly representative.
Accountability
Powell (2000) argues that electoral accountability exists when i) there is clarity of responsibility for political outcomes, and ii) voters can effectively sanction those responsible for those outcomes. Plurality electoral systems tend to score highly on these criteria for two reasons:
- Plurality electoral systems tend to produce single-party majority governments, making it obvious which party is responsible for political outcomes.
- The translation of votes to seats under plurality electoral systems tends to be such that a small loss of votes can result in a significant loss of seats. Voters can thus inflict significant punishment on the incumbent merely by withdrawing a few percentage points of the vote.
PR does not perform as well on these criteria. Firstly, PR tends to produce coalition governments, and where several parties control government it is more difficult for citizens to apportion credit or blame for political outcomes (Powell and Whitten 1993; Duch and Stevenson 2008). Secondly, the relationship between votes and seats under PR is neither as steep as under plurality rule nor so determinative of government status. This is because a party’s ideological position may grant it legislative bargaining power in excess of its seats share. Parties in this advantaged position are thus somewhat insulated from shifts in their vote shares.
These arguments imply a trade-off between representation and accountability. This is depicted in Figure 2. Only if this trade-off takes the form of the bold diagonal line are we really prevented from rank-ordering electoral systems, however. To see this, let A and B represent two hypothetical electoral systems. Observe that A is as accountable as an electoral system could possibly be given its (high) level of representation, and that B is as representative as an electoral system could possibly be given its (high) level of accountability. Trading A for B does not, therefore, result in a better electoral system; it merely changes the mixture of accountability and representation one gets.
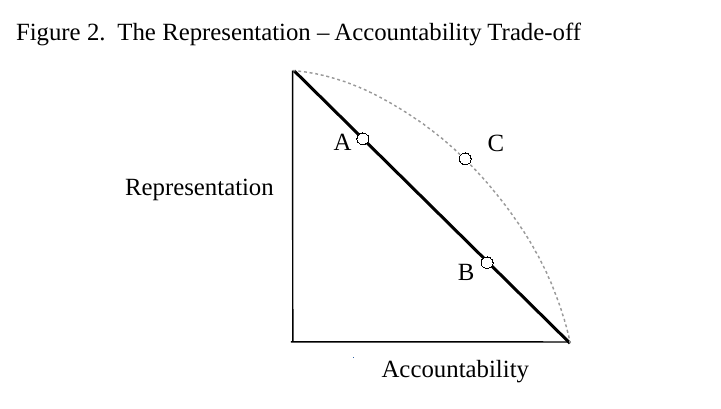
Carey and Hix (2011) point out that the relationship between representation and accountability need not be unyielding; it could be curvilinear as indicated by the dashed line in Figure 2. If so, there may exist an optimal electoral system, such as C. Observe that if you were to replace C by another electoral system (i.e., any spot northwest or southeast of C on the dashed line), both representation and accountability would decline. In this respect, C offers the best feasible mixture of representation and accountability.
PROBLEM 1: MEASURING REPRESENTATION
Even were Carey and Hix’s optimistic view of the trade-off between representation and accountability to obtain, we would have to be able to measure representation and accountability accurately to identify an optimal electoral system. This is not a trivial task.
Social choice theory considers how individual preferences combine to form collective choices. A central result in social choice theory is that one cannot assume the transitivity of collective choices (Arrow 1951). What does this mean? Let’s say that three parties (A, B and C) contest a majority run-off election, and further that a majority of voters prefer A to B and B to C. Social choice theory tells us that we cannot subsequently assume that there exists a majority for A over C; order the run-off differently or use a different electoral system (e.g., plurality rule or ranked ballots), and C could come out on top.[1] This is a troubling result because it suggests that we cannot know whether an election result is representative – in the sense that it reflects the “will of the majority” – or due merely to the vagaries of a particular electoral system.
Collective choices are almost certainly intransitive whenever voters evaluate more than two ballot options along several dimensions, such as when voters consider not only a party’s economic position but also its stance on regional autonomy or the charisma of its leader (McKelvey 1976). In contrast, we can be reasonably sure that collective choices are transitive whenever voters have single-peaked preferences (Sen 1966). This jargon implies that we can order voters in a single line such that all voters strictly prefer options (i.e., parties, candidates) that are closer to their position in the line to options further away.
Whether or not voters have single-peaked preferences is an empirical question. However, it is difficult to assess representation even when voters’ preferences are single-peaked. Figure 3 depicts two stylized electorates, A and B. The shaded blocks represent the ideological range of voters in each electorate.[2] Thus, electorate A is moderate, with most voters just a bit to the left or right of the median voter (MV). In contrast, electorate B is polarized, with many voters located far to the left or right of the median voter. Elections place the median legislator (ML) as far away from the median voter in A as in B, and by that metric the electoral outcomes in A and B are equally representative.
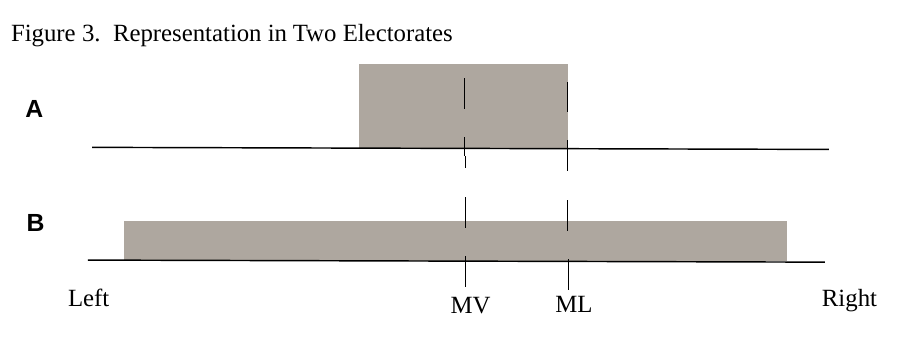
The claim that the electoral outcomes in A and B are equally representative comes about because our measure of representation (congruence) ignores the variance in voters’ preferences. A different view is that the electoral system in B has located the median legislator much closer to the median voter relative to the (wide) range of the electorate’s preferences than has the electoral system in A. Indeed, the electoral system in A has located the median legislator at one extreme of voters’ preferences. This reasoning suggests that we ought to evaluate congruence relative to the range of voters’ preferences. Golder and Stramski (2011) do this, and find that judgments about the relative capacity of different electoral systems to deliver representative outcomes depends on how we measure representation. If we measure representation in terms of the simple distance between the median voter and median legislator, PR electoral systems outperform majoritarian systems. However, once we account for the range of voters’ preferences this difference disappears.
PROBLEM 2: ELECTIONS MAY NOT DELIVER ACCOUNTABILITY
Electoral accountability is often seen to take the form of an implicit contract between voters and incumbents in which voters promise to re-elect incumbents only if their performance exceeds some standard (ill-defined or idiosyncratic as it may be). Of course, voters would also prefer to elect better rather than worse candidates. Fearon (1999) argues that voters are unable to use elections to simultaneously motivate incumbents and select “good” candidates.
Fearon’s argument is based on a stylized 3-stage election cycle in which:
- An incumbent sets a policy, e.g., a target-level of unemployment. Voters want this policy to produce a particular outcome (e.g. zero unemployment), but they cannot precisely discern the degree to which the outcome is due to the incumbent’s policy or to other forces (e.g., world markets).
- After observing the policy outcome, voters either re-elect the incumbent or elect a replacement.
- The politician elected at Stage 2 sets another policy and the electoral cycle ends in a manner akin to the two-term limit that applies to American presidents.
At issue is how voters can cast their votes at Stage 2 to ensure that they get policy they want given three possible challenges. The first challenge is to differentiate between “competent” politicians who can actually achieve the desired policy outcome and incompetent politicians who cannot. The second challenge is to motivate politicians, all of whom prefer a different outcome than voters (perhaps because it’s hard work give voters what they want). The third challenge is a combination of the previous two, i.e., voters must both identify competent politicians and motivate reluctant incumbents.
Fearon shows that voters can meet the first two challenges by setting some standard, and re-electing the incumbent if achieve that standard. For example, the voters say “We prefer zero unemployment, but if you deliver unemployment below 3 percent, we’ll re-elect you.” This rule is sufficient to meet the first two challenges, that is, it allows voters to distinguish competent from incompetent incumbents in the first case, and to motivate reluctant politicians in the second case.
Surprisingly, however, this voting strategy fails in the third case. The problem is that under such conditions voters cannot stick to their promise of re-electing an incumbent who achieves their standard. To see this, observe that a re-elected incumbent will not work to deliver the policy that voters want at Stage 3 because the reward and motivation of re-election no longer apply. The voters’ choice is thus between an incumbent whom they know will ignore their policy preferences, on one hand, and a potentially competent challenger, on the other; voters always prefer the latter and so the incumbent might as well ignore the voters’ preferences at the outset. With all incumbents, competent or not, behaving this way, the electorate cannot distinguish which are competent and which are not.[3] Elections thus fail to motivate incumbents or identify “good” candidates.
CONCLUSION
The fundamental problem in evaluating electoral systems in terms of these criteria is not necessarily that there exists an unyielding trade-off between representation and accountability. It is that we cannot reliably distinguish representative from unrepresentative electoral outcomes, either because these outcomes are products of a voting cycle or because our measures of representation are ambiguous. The situation is no better with regard to accountability; even if we can state that the clarity of responsibility and the capacity to sanction incumbents is better under electoral system x than under electoral system y, there is no assurance that such conditions are sufficient to motivate or constrain office-holders. It seems that we lack reliable means to connect electoral systems to two of the key guiding principles of representative government. While this is a pessimistic conclusion, it should encourage citizens to carefully scrutinize politicians’ claims that some electoral systems are inherently “fairer”, “more democratic, “representative” or “effective” than others.
REFERENCES
Arrow, K. J. (1951). 1963. Social choice and individual values. Wiley, New York.
Carey, J. M., & Hix, S. (2011). The Electoral Sweet Spot: Low‐Magnitude Proportional Electoral Systems. American Journal of Political Science, 55(2), 383-397.
Downs, A. (1957). An Economic Theory of. Democracy, 599-608.
Duch, R. M., & Stevenson, R. T. (2008). The economic vote: How political and economic institutions condition election results. Cambridge University Press.
Fearon, J. D. (1999). Electoral accountability and the control of politicians: selecting good types versus sanctioning poor performance. Democracy, accountability, and representation, 55, 61.
Golder, M., & Stramski, J. (2010). Ideological congruence and electoral institutions. American Journal of Political Science, 54(1), 90-106.
Horowitz, Donald L. (2003). “Electoral Systems: A Primer for Decision Makers.” Journal of Democracy 14: 115-127.
McKelvey, R. D. (1976). Intransitivities in multidimensional voting models and some implications for agenda control. Journal of Economic theory, 12(3), 472-482.
Powell Jr, G. B., & Whitten, G. D. (1993). A cross-national analysis of economic voting: taking account of the political context. American Journal of Political Science, 391-414.
Powell, G. B. (2000). Elections as instruments of democracy: Majoritarian and proportional visions. Yale University Press.
Sen, A. K. (1966). A possibility theorem on majority decisions. Econometrica: Journal of the Econometric Society, 491-499.
[1]Formally, Arrow’s Theorem tells us that any electoral rule that respects certain minimal fairness criteria admits the possibility of an intransitive social choice.
[2]The fact that one can represent the preferences of voters in A and B as points along a straight line implies that they have single-peaked preferences.
[3]The reason that voters can stick to their promise in the first two scenarios is as follows. Under the first scenario (i.e., when some politicians are competent and others not), voters can set a performance standard such that only competent incumbents are likely to be able to meet it. And if the odds are that the incumbent is competent, the voters have every incentive to prefer them to a challenger who is as likely to be incompetent as not.
Under the second scenario, (i.e., all politicians are equally reluctant to carry out the voters’ preferred policy), voters know that any re-elected incumbent will do just as they please in their second term. Thus, to properly motivate the politician in the first term, the voters must be able to credibly promise re-election given adequate performance in the first term. Voters can stick to this promise because on all other grounds they are exactly indifferent between incumbents and challengers. Given this indifference, it is clearly in the voters’ interest to maintain their re-election promise.