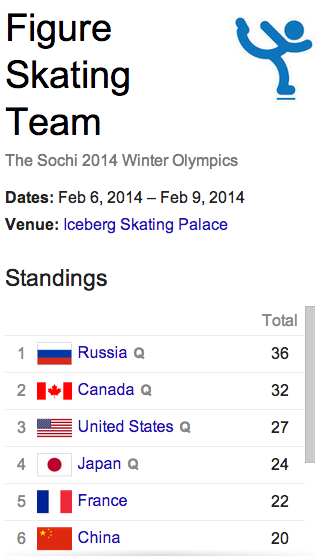
I couldn’t get through this project of learning about evaluation from the Olympics without a mention of curling. Born on the Canadian prairies, I curl! We curled during phys ed class and as a young adult it was an important context for socializing. Curling is a polite game, winning is important but good sportsmanship is more important ~ players are on their honour and there are no judges or referees. And what other sport has a tradition of all the competitors getting together after the match for rounds of drinks, what is called “broomstacking.” Maybe it’s an easy game to make fun of, but try it and you’ll discover there’s more to it than it seems.

Curling is a sport that has many skills that can be isolated, practice and mastered. Like drawing to the button, or peeling off a guard, or a take out with a roll behind a guard, or throwing hack weight. And there’s learning to know when to sweep and yell at the top of your lungs, “hurry, hurry hard!” Countries relatively new to the sport focus on these skills and demonstrate extraordinary abilities of execution, which is important to winning. But winning the game also requires something more elusive. These teams often confuse fidelity with quality, an all too common mistake in program evaluation. Being able to execute shots with precision is necessary, but not sufficient to win, in either curling or programs.
Strategy is also key in curling and is not so easily mastered through repetitious practice of isolated skills. Curling has been called “chess on ice.” There are aggressive and conservative strategies. Strategy depends in large part on the context ~ factors such as the ice, skill levels, whether you have the hammer (the last rock thrown), and so on. Strategy in program delivery, especially on the ground interpretations and practice, also depends on the context and practitioners use their strategic knowledge to adjust interventions to achieve maximum success. This strategic adjustment must often trade away fidelity to the intervention plan or map, and too frequently this is seen as a failure. Program evaluations sensitive to both programmatic intentions and local variation are more comprehensive and meaningful for understanding how and why programs work, or don’t.