
Being an inherently data-driven solution, machine learning (ML) models can aggregate and process vast amounts of data, such as clinical files and financial records. With the growing application of ML-based solutions in privacy-sensitive domains such as healthcare, the potential privacy ramification of training DL models on sensitive data stands out as a notable concern.
To this end, membership inference attacks (MIAs) represent a prominent class of privacy attacks that aim to infer whether a given data point was used to train the model.
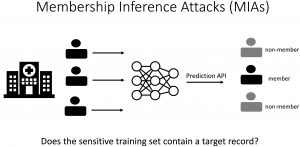
MIAs constitute a fundamental threat to data privacy, e.g., if the model is trained on a sensitive population such as patients with a rare disease, then merely divulging that some individual is part of that population may become a severe privacy risk.
This project studies MIAs from both a defensive and adversarial perspective.
Practical Defense against Membership Inference Attacks
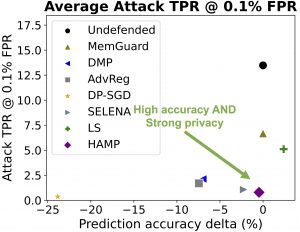
We introduce HAMP, a defense technique that can achieve strong membership privacy and high accuracy. To mitigate MIAs in different forms, we observe that they can be unified as they all exploit the ML model’s overconfidence in predicting training samples through different proxies. This motivates our design to enforce less confident prediction by the model, hence forcing the model to behave similarly on the training and testing samples.

We show that HAMP simultaneously achieves strong privacy protection against a range of existing MIAs (y-axis) and minimal accuracy degradation (x-axis).
Zitao Chen and Karthik Pattabiraman, Overconfidence is a Dangerous Thing: Mitigating Membership Inference Attacks by Enforcing Less Confident Prediction. Proceedings of the Network and Distributed Systems Security Conference (NDSS), 2024. (Acceptance Rate: 15%). Artifacts Available, Functional and Reproduced
What’s next?
Nevertheless, many existing studies assume the ML models are trained without being adversarially manipulated; whereas a capable adversary may compromise the models to achieve a desired outcome such as amplifying privacy leakage. This motivates the second contribution of this project.
Supply chain Attack to Facilitate Stealthy and High-power Membership Inference Attacks
Modern machine learning (ML) ecosystems offer a surging number of ML frameworks and code repositories that can greatly facilitate the development of ML models. Today, even ordinary data holders who are not ML experts can apply an off-the-shelf codebase to build high-performance ML models on their data, which are often sensitive in nature (e.g., clinical records).
In this work, we consider a malicious ML provider who supplies model-training code to the data holders (e.g., by injecting compromised code into public repositories as shown in recent real-world incidents [example1, example2]), does not have access to the training process, and has only black-box query access to the resulting model.
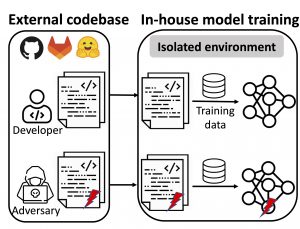
Under this setting, we demonstrate a new form of membership inference attack that is strictly more powerful than prior art.
The core idea of our attack is to exploit the model’s memorization capacity, and strategically have the model memorize an additional set of secret (synthetic) samples, whose outputs can be leveraged to encode the membership of the training samples.
Our attack highlights four key features:
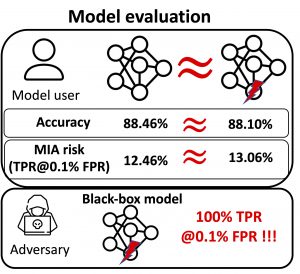
- Near-perfect MIA success (high true positive and low false positive).
- MIA is easy to perform (no reliance on shadow models for calibration).
- Minimal accuracy degradation.
- Stealthy privacy leakage: The amplified privacy leakage can only be revealed under a specialized form of MI process known by the adversary; otherwise the poisoned models would exhibit comparable privacy leakage as the non-poisoned counterparts, under common MIA methods.
Zitao Chen and Karthik Pattabiraman, A Method to Facilitate Membership Inference Attacks in Deep Learning Models. To Appear in the Proceedings of the Network and Distributed Systems Security Conference (NDSS), 2025. (Acceptance Rate: TBD).