
Contact: Abraham Chan, 
Leveraging Explainable AI tO Provide Resilience for ML Ensembles at Inference
While ML ensembles have been shown to provide resilience against faulty training data faults, they can nevertheless mispredict with simple majority voting. Instead of simple majority voting based solely on outputs, we propose an alternative – dynamically weighted ensembles where weights are determined based on the constituent models’ feature diversity. We present this as ReMlX, a framework that reexamines ML decisions by ensembles using explainable AI (XAI) techniques.

Abraham Chan, Arpan Gujarati, Karthik Pattabiraman and Sathish Gopalakrishnan, ReMlX: Resilience for ML Ensembles using XAI at Inference against Faulty Training Data. IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), 2025. (Acceptance Rate: 20%) [ PDF | Talk ] (code)
EFFICIENT Diversity-guided Search for Resilient ML ensembles
ML ensembles have been shown to be resilient against training data faults. However, there are many different ways to generate ML ensembles, and their accuracy can significantly differ. This creates a large searchspace for ensembles, making it challenging to find ensembles that maximize accuracy despite training data faults. We identify three different ways to generate diverse ML models, and present D-semble, a technique that uses Genetic Algorithms and diversity to efficiently search for resilient ensembles.

Abraham Chan, Arpan Gujarati, Karthik Pattabiraman and Sathish Gopalakrishnan, D-semble: Efficient Diversity-Guided Search for Resilient ML Ensembles. ACM International Symposium on Applied Computing (SAC), 2025. Safe, Secure, and Robust AI Track. (Acceptance Rate: 23%) [ PDF | Talk ] (code)
Evaluating the Effect of Common Annotation Faults on Object Detection Techniques
Many ML applications in safety-critical domains require object detection, which includes both classification and localization, to provide additional context. To ensure high accuracy, state-of-the-art object detection systems require large quantities of correctly annotated images for training. However, creating such datasets is non-trivial, may involve significant human effort, and is hence inevitably prone to annotation faults. We evaluate the effect of such faults on object detection applications.
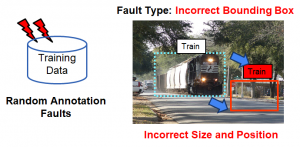
Abraham Chan, Arpan Gujarati, Karthik Pattabiraman and Sathish Gopalakrishnan, Evaluating the Effect of Common Annotation Faults on Object Detection Techniques. IEEE International Symposium on Software Reliability Engineering (ISSRE), 2023. (Acceptance Rate: 29.5%) [ PDF | Talk ] (Code)
COMPARING ML MITIGATION TECHNIQUES AGAINST FAULTY TRAINING DATA
Machine learning (ML) has been adopted in many safety-critical applications like automated driving and medical diagnosis. The correct behaviour of a ML model is contingent upon the availability of well-labelled training data. However, obtaining large and high-quality training datasets for safety-critical applications is difficult, often resulting in the use of faulty training data. We compare the efficacy of five different error mitigation techniques, which are designed to tolerate noisy/faulty training data.
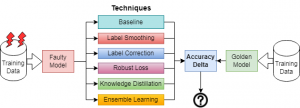
Abraham Chan, Arpan Gujarati, Karthik Pattabiraman, and Sathish Gopalakrishnan. The Fault in Our Data Stars: Studying Mitigation Techniques against Faulty Training Data in ML Applications, IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), 2022. (Acceptance rate: 18.7%) [ PDF | Talk ] (Code)
Evaluating how ensembles improve ML resilience
Machine learning applications are deployed in many critical domains today. Unlike programmed software, the behaviour of ML applications is based on the training data provided. However, training data can be faulty, whether through human mistakes during data collection or through automated labelling.
Therefore, it is important to understand how faulty training data affect ML models, and how we could build more robust ML models to mitigate their effects.
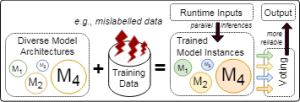
Abraham Chan, Niranjhana Narayananan, Arpan Gujarati, Karthik Pattabiraman, and Sathish Gopalakrishnan, Understanding the Resilience of Neural Network Ensembles against Faulty Training Data, Proceedings of the IEEE International Symposium on Quality, Reliability and Security (QRS), 2021. Full paper (Acceptance Rate: 25.1%) [ PDF | Talk | Video ] (Code) Best Paper Award (1 of 3).
Training Data Faults
Machine learning (ML) is widely deployed in safety-critical systems (e.g. self-driving cars). Failures can have disastrous consequences in these systems, and hence ensuring the reliability of its operations is important. Mutation testing is a popular method for assessing the dependability of applications and tools have recently been developed for ML frameworks. However, the focus has been on improving the quality of test data. We present an open source data mutation tool, TensorFlow Data Mutator (TF-DM), which targets different kinds of data faults for any ML program written in TensorFlow 2. TF-DM supports different types of data mutators so users can study model resilience to data faults.
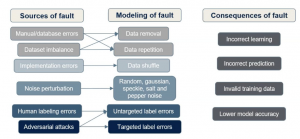
Niranjhana Narayanan, and Karthik Pattabiraman, TF-DM: Tool for Studying ML Model Resilience to Data Faults, DeepTest, 2021. [ PDF | Code]
N-Version Programming in Machine Learning
We revisit N-Version Programming (NVP) in the context of machine learning (ML). Generating N versions of an ML component does not require additional programming effort, but only extra computations. This opens up the possibility of executing hundreds of diverse replicas, which, if carefully deployed, can improve their overall reliability by a significant margin. We use mathematical modeling to evaluate these benefits.
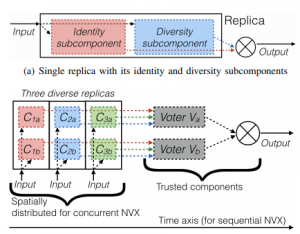
Arpan Gujarati, Sathish Gopalakrishnan, and Karthik Pattabiraman, New Wine in an Old Bottle: N-Version Programming for Machine Learning Components, IEEE International Workshop on Software Certification (WoSoCER), 2020. Held in conjunction with the IEEE International Symposium on Software Reliability Engineering (ISSRE), 2020. [PDF][Talk]