
Motivation
In our digital age, ML models are the new superheroes, saving the day in critical systems like healthcare, autonomous driving, and even aviation. But just like any superhero, they need to withstand pressure and perform reliably, even when faced with the archenemy of hardware faults. This underlines the exciting necessity of digging deeper into the reliability of the ML models under hardware faults.
Summary
In this project, we explored three directions for resilience analysis of ML models, covering different types of ML models (DNNs vs. Large Language Models), as well as hardware platforms (CPU vs. DNN accelerators). First, we built LLTFI, a Framework-Agnostic Fault Injection (FI) tool for ML applications, which we used to assess the reliability of DNNs and evaluate the efficacy of Selective Instruction Duplication (SID) for protecting ML models against transient faults in CPUs. Second, we extended LLTFI to support FI in Large Language Models (LLMs) like Bert and GPT3, using which we evaluate the resilience of LLMs against transient faults. Finally, we built an RTL-level fault injector that we use to study the effect of hardware faults in DNN accelerators. Through exhaustive FI experiments, we unearthed several differences between DNNs and LLMs in terms of their resilience. Moreover, unlike CPUs, for DNN accelerators, we observed hardware faults manifest as well-defined fault patterns at the intermediate layers of the DNNs. In conclusion, the observations made in this project improve our understanding of the fault-tolerance of ML models and can also be used to develop fault-tolerant hardware and software systems, thus making ML more suitable for safety-critical domains.
In the following sections, we have further elaborated on each part of this project:
Precise, software-based Fault Injection in ML Models
Existing software-level fault injection tools suffer from two problems:
- Framework Specific: Existing tools like TensorFI and PytorchFI are tied to just one ML framework: TensorFI works only with Tensorflow, while PyTorchFI works only with the PyTorch framework.
- Inaccurate: Tools like TensorFI and PyTorchFI are application-level, i.e., they inject fault in the output of ML operators. They implicitly make the assumption that all hardware transient faults end up corrupting the output of ML operators. However, this assumption is wrong, as we empirically demonstrate in this project.
To overcome these limitations, we propose LLTFI, a framework-agnostic, software-level tool that injects faults in the instructions and registers of the ML model.
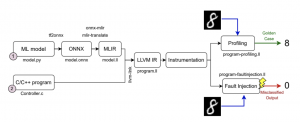
LLTFI’s Working
The figure above shows LLTFI’s working. The trained ML models are first exported to a saved model format (like TensorFlow SavedModel) and then to the ONNX format. Afterward, the ONNX file is converted into LLVM IR using the ONNX-MLIR tool. After this step, LLTFI can inject faults into the LLVM IR of the model at runtime without requiring recompilation. We evaluated LLTFI with six popular ML programs and compared it to TensorFI, a high-level FI tool for ML programs. We found that TensorFI underestimates the reliability of ML programs for single bit-flip faults by 3.5X on average compared to LLTFI. Finally, we found LLTFI to be 27% faster than TensorFI on average.
Learn more about LLTFI here. LLTFI is open-source on GitHub: https://github.com/DependableSystemsLab/LLTFI
Got questions about LLTFI? Ping me (Udit) over the email given at the end of this post.
Understanding Reliability of Large Language Models (In Progress)
Large Language Models (LLMs) are reshaping the landscape of natural language processing and drastically altering how machines communicate with people. LLMs such as ChatGPT and Google’s Bard have already made substantial progress in the realm of conversational AI, allowing machines to comprehend natural language and reply in a way that is more akin to human interaction. Beyond common uses like sentiment analysis and generating text, LLMs are also employed in safety-critical applications like creating code and understanding spoken instructions in self-driving cars, where dependability is crucial.
We used LLTFI to assess the resilience of LLMs against transient hardware faults. We used five LLMs consisting of Bert, GPT2, T5, etc. We found that LLMs are quite resilient to transient faults overall, and their behavior varies significantly with the input, LLM’s architecture, and the type of task (e.g., translation vs. fill-in-the-blank).
For instance, consider T5 LLM under transient faults:
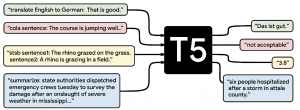
T5 LLM
[INPUT Prompt]. Translate English to French: The House rose and observed a minute’s silence
[Correct Output] L’Assemblée se levera et observera une minute de silence
[Semantically-correct Output #1] Le Parlement se levera et observera une minute de silence
[Semantically-incorrect Output #2] zaharie a eu l’occasion de s’exprimer
Due to the injected fault, T5 gave both semantically correct and semantically-incorrect outputs, as shown above. Semantically incorrect outputs can have hazardous consequences for safety-critical applications as, unlike syntactically incorrect outputs, they are difficult to detect and prune.
This work is in progress, so stay tuned for more exciting results!
Understanding the effects of stuck-at faults in ML Accelerators
LLTFI, TensorFI, and several other software-level FI tools are constrained to introducing faults specific to the CPU hardware model. However, in order to enhance the speed of training and inference for large DNNs and LLMs, DNN accelerators like Google TPU are widely utilized in practical applications. Previous research on evaluating the resilience of ML models against hardware faults in DNN accelerators has been limited to assessing the accuracy of the DNNs in the presence of faults. However, it remains unclear how these faults manifest at the intermediate layers of the DNNs. This understanding is crucial because comprehending the manifestation of faults at the intermediate layers offers valuable insights into constructing more robust DNN architectures and improving the accuracy of fault injection tools at the application level.
We bridge this gap by proposing a Register Transfer (RTL) Level FI tool to inject permanent stuck-at faults in DNN accelerators, using which we evaluate the manifestation of injected faults on the intermediate layers of the DNNs. We found several interesting manifestations of stuck-at faults. For instance, the following figure shows the fault pattern in the convolution operator due to stuck-at fault in hardware. Due to stuck-at faults, several output channels of convolution got corrupted (highlighted in RED).
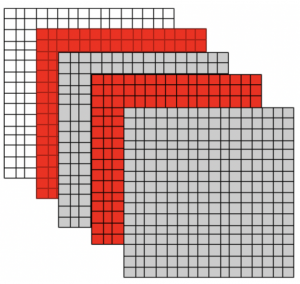
Learn more about this work here.
Team
Udit Agarwal (uditagarwal1997@gmail.com)
Abraham Chan (abrahamc@ece.ubc.ca)
Papers
[1] Udit Kumar Agarwal, Abraham Chan, Ali Asgari, and Karthik Pattabiraman. 19th IEEE Workshop on Silicon Errors in Logic – System Effects (SELSE), 2023. Received Best-of-SELSE award (one of three papers). To be published in Dependable Systems and Networks (DSN) 2023’s supplementary proceedings. (Reference: LINK)
[2] Udit Agarwal, Abraham Chan, and Karthik Pattabiraman. LLTFI: Framework Agnostic Fault Injection for Machine Learning Applications (Tools and Artifact Track) IEEE International Symposium on Software Reliability Engineering (ISSRE), 2022. (Reference: LINK)
[3] Abraham Chan, Udit Agarwal, and Karthik Pattabiraman. (WiP) LLTFI: Low-Level Tensor Fault Injector. IEEE International Workshop on Software Certification (WoSoCER’21), co-held with the IEEE International Symposium on Software Reliability Engineering (ISSRE), 2021. (Reference: LINK)