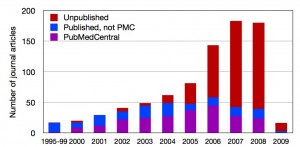
Genomics and metagenomics describes the study of an organism’s complete genetic data set, with emphasis on sequence mapping. The former is limited to the study of organisms that can be isolated in pure culture, whereas the latter applies to an entire community of microbes in their native environment. Technological advancements have facilitated a data explosion; genomic maps are now being produced at a faster rate than the existing publication infrastructure can accommodate. The result is a loss of data, contextual metadata and annotation. Essentially valuable data is disappearing before it can be interpreted or see the light of publication.
Number of published journal articles per year relating to the complete genome sequences of bacteria and archea
SIGS is a GSC initiative to attempt to bridge this gap, by producing concise peer-reviewed reports that comply with MIGS/MIMS standards, in addition to operation procedures, commentary and review articles. Minimum Information about a (Meta)Genome Sequence (MIGS/MIMS) is a GCS initiative to expand on core reporting standards already established by the International Nucleotide Sequence Database Collaboration (INSDC). MIGS/MIMS is characterized by a standardized checklist that has been published in its entirety in Nature Biotechnology. SIGS will attempt to keep up with data production by offering an accelerated editorial revision workflow, where copy-editing begins almost immediately after initial acceptance.
Editorial Workflow
The e-journal’s goal is to produce 600 publications by June 2011 (approximately 30 per month), by attracting internationally credible authors under a cost-effective model for an open-access journal.
A sample short genomic report was then described, in conjuction with MIGS/MIMS standards. The anatomy of a report included a abstract and introduction (a), genetic sequencing information (b) genome properties (c) and comparisons with previously sequenced genomes (d). Lastly, conclusions and references (e).
Ms. Susan Murray is a proactive individual working with the African Journals Online (AJOL), a non-profit organization, as the executive director for over two years. Her she academic background is on development economics and she is focused on opening access to information in developing countries such as Africa.
Session Overview
Ms. Murray’s session is a journey from the 1990s to present day focusing on the progression of access to African Journals Online (AJOL) (Session Abstract). She begins with an overview of the journal, followed by the users and stakeholders involved, which she ties in to a comparison of the old and new systems along with the future outlook for AJOL, and finally she concludes the presentation with a business plan and parting remarks.
(1) Overview of AJOL
Ms. Susan Murray started the presentation with the following quote from Mamphela Ramphele :
“There is no way we can succeed in the eradication of poverty if the developing world is not part of knowledge creation, its dissemination and utilization to promote innovation. Higher education is a critical factor in making this possible and must be part of any development strategy.”
– Mamphela Ramphele (2000)
Ms. Murray goes on to explain the importance of higher education and policies governing such institutes. She indicates that there is a long way to go in terms of sharing and transferring knowledge to the developing worlds, however it must be done and there is harm in not doing so as innovation cannot advance in these developing countries. In Africa the process of dissemination has already begun with AJOL hoping to increase its visibility and accessibility of open journal sources. Currently, AJOL has 350 titles with over 40000 articles (and free metadata) which are a combination of open-access (OA) and subscription based titles that cover majority of the academic spectrum. Ms. Murray pointed out that some of the titles are not found online anywhere else but on AJOL! This shows the exclusivity of some of the titles that are secured by AJOL. In order to join AJOL, Ms. Murray listed the following criteria which must be adhered to – this mostly encourages more of the ‘fringe’ journals to upload their documents for increased visibility:
Must be original research
Needs to be peer-reviewed
All content must be given to AJOL
Permission must be granted to AJOL
Content must be published in the African continent
(2) The Stakeholders
It is fascinating to know that as of today, Ms. Murray highlighted the 26 African countries with journals on AJOL (See Figure 1a). Figure 1b is a ‘Google Maps mashup’ which highlights the actual journals (with corresponding links) in a particular country. Ms. Murray exclaimed this is an impressive display along with the number of visits by other continents as illustrated in Figure 2. Africa had the highest percentage of visitors at 32% of the total population who accessed the site, while North America, Asia, and Europe had 23%, 21%, and 20% respectively.
Figure 1a: Distribution of Journals in Africa (used with permission from Ms. Murray)
Figure 2: Visits by continent (used with permission from Ms. S. Murray)
Ms. Murray further elaborated that the users comprise mostly of professionals, publishers, researchers, librarians, professors, and teachers. Since moving to the new open journal system 2.2.2 (OJS 2.2.2) platform there has been a significant increase in the number of users over a period of three months. In April 2009 the number of users was 57123 while in June 2009 there were an astounding 81852 users accessing the journals on AJOL – an increase in approximately 38%. During the discussion of the users, Ms. Susan Murray brought up an important issue related to the key stakeholders involved in the journal dissemination and access regime. This involves the researchers who need access to the scholarly journals to advance ideas in a particular field of study, and the journal editors want increased visibility in the public domain to encourage wide readership of their documents. This give and take is successfully propelled by the joint involvement of AJOL and the Public Knowledge Project (PKP). Ms. Murray explained how AJOL reduced costs and increased the quality of the journal in order to publish the full text documents online. These two factions, AJOL and PKP, attempt to meet the needs of both the researcher and the journal editors to ensure a balance in the system by providing quality journals to the masses.
(3) Comparison of old and new systems
After the overview and elaboration of the users and stakeholders of AJOL, Ms. Murray went into the details of the AJOL on OJS 2.2.2. She expressed the benefits of such a partnership with PKP led to better upgrading of the system. She found that more advanced versions could also be complied and were easier to upload which allowed for more capabilities in the platform that were not possible before. Figure 3 shows flowchart of the software and resources used ending with final product of the Open Journal Systems coded through the PHP scripting language using MySQL as the database management tool in the APACHE web browser run from the Linux operating system.
Figure 3: Software and Resources (created by Pam Gill)
A comparison of the new and old system is shown in Figure 4. The new approach is useful for all parties involved and is an excellent search tool with a new look and feel. Currently, as of July 2009, journals now manage their own AJOL pages in terms of the workflow management. In the future, Ms. Murray envisions that journals will be able to host their own versions of OJS on the PKP harvester which acts as a metadata aggregator. The newer versions will include a statistics package and offline plug-ins when connectivity is interrupted. The offline plug-in option will be crucial for users living in remote areas. Eventually, Ms. Murray envisions all journals being independent and managing their own pages.
Figure 4: Comparison Chart of Old and New Systems (created by Pam Gill)
(4) Final remarks
To conclude her presentation, Ms. Murray placed great emphasis on the need for the flow of global information from the North to the South (Evans and Reimer, 2009). She stressed the implementation of a new business plan that would allow journals to consider OA as a more viable possibility via AJOL/PKP. The full OJS functionality on AJOL has already made a huge difference as discussed earlier as open source software (OSS) has matured considerably. To summarize Ms. Murray ended her presentation one two key points to promote and continue the dissemination of literature in developing countries. First she brought forth the importance of carefully selecting the best tool that will take into account the needs of the users. Next, she advised to carefully align yourself with partners that you trust and who will support your initiatives for the right reasons. The following quote from Ms. Susan Murray herself summarizes these points:
“Relationships and communication are still the drivers of success, the technological tools are just the vehicle.”
– Susan Murray (2009)
This quote from Ms. Murray is used to illustrate that the technology can help propel the dissemination process in varying capacities. Technology depends on the specifications and limitations of the hardware and software. Yet, at the end of the day, relationships with others are the most important in terms of communicating, working collaboratively sharing ideas, which will ultimately lead to the success (or failure) of your goals and aspirations.
Questions from the audience asked at Ms. Murray’s session:
Question: Is AJOL published in other languages (referring to Figure 1 of African map from Susan’s PowerPoint slide)? Does AJOL have plans to bring more non-English journals to the portal?
Answer: Yes, we are hoping to introduce this to Francophone countries by starting the process of translating to French. So there will be an English/French option. We have a few journals published in Portuguese, Arabic. If we have a journal that is online (and space is NOT a problem) then we can publish in a local, indigenous and international language. Then at the same time research can be read by the local community and broadly by the rest of the world. This will increase readership and the journal will have met the needs to satisfy the best of both worlds.
Mr. Edgar presented the preliminary results from a survey of over 1,000 OJS editors around the world. The goals behind the survey were to gather information about who is using the journals, where they are located, and to gain a sense of their funding models as well as what motivates them to do this work,
While the data analysis is still in the preliminary stages, Mr. Edgar presented some of the survey results and commented on a number of the findings as follows:
South America, Europe, and North America (in descending order) accounted for 75% of the journals
Almost half the journals were in the Social Sciences with Health Sciences and Technology and Engineering the next most common topic areas
More than half the journals were sponsored by academic departments and another third by scholarly associations
The rate at which the journal accepted articles was quite variable with roughly equal numbers distributed across all the acceptance rate bands
A very high percentage of the journals used editorial and double blind review procedures
In most of the journals, the editor is personally responsible for copy editing, layout, and proofreading
But it is not a full-time job for the editors. In 80% of the journals, editing requires less than ten hours per week.
Most of the journals reported small (or zero) expenses and revenues. However, a small percentage reported more than $50,000 in both. Mr. Edgar commented that these zero expense journals seem to indicate a new model for journal publishing becoming possible
For those journals that generated revenue, it mostly came from institutional funding, followed by subscriptions, and then from advertising
Most of the editors were motivated to do their work due to a desire to provide new knowledge and a service to the community and not for financial benefit
While 83% of the journals qualified for inclusion in the Directory of Open Access Journals (DOAJ), only 22% actually were included
Around 40% of responders continued to produce print journals
Questions and Audience Comments
A lively discussion ensued following Mr. Edgar’s presentation. Some of the key points are as follows:
While the data analysis is still preliminary, they hope to have a more complete analysis by the fall of 2009.
One audience member asked how many of the OJS journals were included in the ISI. The original survey didn’t ask about inclusion in the ISI, but they did ask about indexing.
There was considerable discussion about why the number of OJS journals in DOAJ is small. One possible explanation is that the DOAJ has a big backlog in evaluating journals for inclusion, so it may be possible that the number of OJS journals in DOAJ will be increase as the backlog is cleared.
There was also much discussion about those institutions reporting zero costs. There are real costs: servers, people’s time, cost of producing the knowledge, etc. But some felt that those costs are rightly viewed as a part of the operating costs of the university and it may be legitimate to not include them specifically in the journal cost. On the other hand, some people need to be able to put a time/cost as part of their justification to create an OJS journal, and they would like to see those costs broken out. An audience member pointed out that the data collected (e.g. hours per week that editors spend on the journal) can be converted to generate this data.
Related Links
The Public Knowledge Project Open Journal System (OJS)
Mr. Martin Boucher highlighted the features and implications of a new publishing platform called Erudit (Session Abstract). He focused on sharing the capabilities of the Erudit publishing platform by first providing a brief historical overview of the organization, describing the publishing process, then introducing Erudit, and concluding with the benefits of such a platform.
(1) Historical Overview
Mr. Boucher started the session by pointing out that Erudit is a non-profit, multi-institutional publishing platform founded in 1998. This platform, based in Quebec, provides an independent research publication service which consists of access to various types of documents in the humanities and social sciences fields to the universities. Erudit also encouraged the development of Synergies which is a similar platform but targets a more mainstream audience since it is published in English. Some facts about Erudit:
International standards are followed
Publishes over 50000 current and back-dated articles
Offers management services, publishing, and subscriptions
90% of the downloads are free
Have over 1 million visits per month
(2) Publishing Process
The description of the publishing process constituted at least a third of the presentation time. Mr. Boucher felt it necessary to take the time to describe to the audience the details involved so it would be easier to compare the similarities and differences between the new and old versions of the system. To begin, Mr. Boucher indicated the publishing process accepted only journals based on extensible markup language (XML), and various input sources (In Design, QuarkXPress, Open Office, Word, RTF). Also, he pointed out that there are no peer-reviews, in fact: only the final documents are considered to be a part of the collection. It should be pointed out that these documents meet high quality standards as they are expected to be peer-reviewed before submitting to the publishing platform. As of yet, Erudit does not have the software to assist in a peer-review type of process. The belief of the Erudit community is to provide quick digital dissemination of the articles. This complicated, lengthy process is made possible by a team of three to four qualified technicians, one coordinator, and one analyst, all of whom ensure a smooth transition of the documents into the virtual domain. The publishing process consists of five key steps as outlined in Figure 1. Mr. Boucher elaborated on the importance of the analysis step. He went on to outline the three steps of the manual semantic analysis. The first consists of manual and automated tagging where detailed XML tagging is only for XHTML, and less tagging is done on PDF files. The second step consists of the automated production of XML files for dissemination. And lastly, a rigorous quality assurance by the technicians prior to dissemination sums up the analysis step of the publishing process.
Figure 1: The publishing process (image created by Pam Gill)
(3) New Erudit Platform
Once the publishing process was described, an illustration of the new Erudit platform was revealed. Mr. Boucher indicated there is now increased support for journal articles through the Erudit Article 3.0 XML schema (see Figure 2). Further, there is support for additional scholarly genres such as books, proceedings, and even online courses (a recent request). It should be mentioned here that some of these other forms of documents are still in the experimental stages such as digitizing books. In addition, there is continued support for other XML input/output formats to ensure preservation and interoperability such as with the Open Archives Initiative (OAI), Google Scholar, and indexing databases.
Figure 2: The new Erudit support system (image created by Pam Gill)
(4) Benefits
To conclude his presentation on Erudit, Mr. Boucher explained the advantages of incorporating such a system by mentioning particular benefits of interest:
Purely Java-based
User-friendly because they have a universal set of tools inside the applications which makes it easier for the support technicians to troubleshoot and work with
Mr. Martin Boucher hinted that the beta version of Erudit was to release in Fall 2009.
Questions from the audience asked at Mr. Boucher’s session:
Question: For the open access subscription of readership which consists of a vast collection, are statistics being collected? Answer: Not sure.
Question: Will the beta version of the publishing platform be released to everyone for bug reporting, testing, or move internally? Answer: Not sure if there will be public access. But it is a good idea to try the beta platform.
Question: Are you considering using the manuscript coverage for the Synergies launch? Answer: The new platform is creatively tight to what we are doing, and it is really close, with Synergies in mind.
Question: In a production crisis, are journal editors with you until the end of the process? Answer: They are there at the beginning of the process. They give material, but we do our own quality assurance process and then we release to the journal, however it is our own control. Also, the editors cannot see the work in the process such as the metadata, thought we do exchange information by emails.
Question: Has the provincial government been generous in funding? Answer: The journals had to publish in other platforms. There is a special grant for that. It is easier for us with that granting repository for pre-prints, documents or data section of the platforms which serve as an agent for them. Yet, Erudit is not considered by the government, although we are trying to get grants from the government. Currently to maintain the platform we only have money for basic management. In order to continue developing platforms (such as Synergy), to get support from the government is difficult.
Question: How do the sales work for the two platforms? Answer: If you buy it, you will have all the content and access increases.
Question: How is it passed to the publisher? Answer: The money goes to the journals, keep only a small amount for internal management since we are a non-profit society.
Question: Could you describe the current workflow and time required to publish one article? Answer: It depends on the article. If we are publishing an article that has no fine grain XML tagging or it is text from a PDF, then it requires less time for us to get it out. It depends on the quality of the article and the associated graphics, tables, size etc. We publish an issue at a time. It takes say two days to get an article published.
Related Links
University of Montreal receives $14M for innovation (news article)
Presenters:Astrid van Wesenbeeck and Martin van Luijt – Utrecht University
Photo taken at PKP 2009, with permission
Astrid van Wesenbeeck is Publishing Advisor for Igitur, Utrecht University Library Martin van Luijt is the Head of Innovation and Development, Utrecht University Library
Powerpoint presentation used with permission of Martin van Luijt
Quote: “We always want to work with our clients. The contributions from our users are very important to us.”
Session Overview
The University Library is 425 years old this year. While they are not scientists or students, they have a mission to provide services that meet the needs of their clients. Omega-integrated searches bring in all metadata and indexes it from publishers and open access areas.
Features discussed included the institutional repository, digitization and journals [mostly open and digital, total about 10 000 digitized archives].
Virtual Knowledge Centers [see related link below]
– this is the area of their most recent work
– shifts knowledge sharing from library to centers
– see slides of this presentation for more detail
The Problem They Saw:
We all have open access repositories now. How do you find what you need? There are too many repositories for a researcher to find information.
The Scenario
They chose to address this problem by targeting the needs of a specific group of users. The motivation – a one-stop shop for users and increased visibility for scientists.
The Solution:
Build an open-access subject repository, targeted at veterinarians, containing the content of at least 5 high-profile veterinarian institutions and meeting other selected standards.
It was organized by cooperating to create a project board and a project team consisting of knowledge specialists and other essential people. The user interface was shaped by the users.
Their Findings:
Searching was not sufficient, the repository content, to use his word, “Ouch!” Metadata quality varied wildly, relevant material was not discernible, non-accessible content existed and there were low quantities in repositories.
Ingredients Needed:
A harvester to fetch content from open archives.
Ingredients Needed 2:
Fetch more content from many more archives, filter it and put it into records and entries through a harvester, then normalize each archive, and put it through a 2000+ keyword filter. This resulted in 700,000+ objects.
Ingredients 3:
Use the harvester, filter it and develop a search engine and finally, a user interface.
Problem: The users wanted a search history and pushed them into dreaming up a way of doing that without a login. As designers, they did not want or need that login, but at first saw no way around a login in order to connect the history to the user. Further discussion revealed that the users did not have a problem with a system where the history did not follow them from computer to computer. A surprise to the designers, but it allowed for a login-free system.
Results: Much better research. Connected Repositories: Cornell, DOAJ, Glasgow, Ugitur, etc.
Workshop Discussion and Questions:
1. How do you design an intelligent filter for searches? [gentleman also working to design a similar search engine] Re-harvesting occurs every night with the PKP harvester rerunning objects through the filter. Incremental harvests are quick. Full harvests take a long time, a couple weeks, so they try not to do them.
2. Do you use the PKP harvester and normalization tools in PKP? We started, but found that we needed to do more and produced a tool outside the harvester.
3. <Question not heard> It was the goal to find more partners to build the tool and its features. We failed. In the evaluation phase, we will decide if this is the right moment to roll out this tool. From a technical viewpoint, it is too early. We may need 1 to 2 years to fill the repositories. If you are interested in starting your own, we would be delighted to talk to you.
4. I’m interested in developing a journal. Of all your repositories, do you use persistent identifiers? How do I know that years down the road I will still find these things? Is anyone interested in developing image repositories? There is a Netherlands initiative to build a repository with persistent identifiers. What about image repositories? No. There are image platforms.
5. Attendee comment: I’m from the UK. If valuable, we’ll have to fight to protect these systems because of budget cuts and the publishers fighting. So, to keep value, we’ll have to convince government about it.
Sophia Jones joined the SHERPA team as European Development Officer for the DRIVER project at the end of November 2006. Since December 2007, she has also been working on the JISC funded Intute Repository Search project.
Jones has a BA in Public Administration and Management (Kent), an MA in Organisation Studies (Warwick) a Certificate in Humanities (Open University) and is currently studying part time for a BA in History (Open University). She is also fluent in Greek. Prior to joining the University of Nottingham, Jones worked as International Student Advisor at the University of Warwick, Nottingham Trent University and the University of Leicester.
Sophia’s interests include international travel, music, cinema and enjoys spending time reading the news of the day.
Vic LyteMIMAS, Director of INTUTE, University of Manchester
Mimas, University of Manchester, +44 (0)161 275 8330vic.lyte@manchester.ac.uk
Vic Lyte is the Director of the Institute Repository Search Project. Lyte is also Development Manager at Mimas and also Technical Services Manager at Mimas National Data Centre. Lyte’s specialty areas are design and development of Autonomy IDOL technology within Academic & Research vertical and advanced search and discovery systems, architectures and interfaces with research and teaching context. Lyte’s work is lead by repository and search technologies.
Session Overview
The UK Istitutional Repository Search (IRS) was initiated after a perceived gap was noticed in the knowledge access search process, where there appeared to be unconnected islands in knowledge materials. The IRS followed on from the intute research project. The high end aims included easier access for researchers to move from discovery to innovation by linking repositories to exchange knowledge materials. The IRS uses two main search methods: a conceptual search and a text-mining search. A question was asked by a member of the audience to differentiate the searches. Jones responded by stating that the conceptual search searches documents, whilst the text-mining search searches within documents.
Jonesa then demonstrated the two types of searches by using an example quesry of ethical research. Searches can be added by suggested related terms, or narrowed down by filtering through repository or document type. The conceptual search results can also be viewed as a 3D interactive visualisation. The text-mining search can also be viewed as an interactive cluster map.
In summary Jones stated that IRS had met all its high end aims. In engaging in a focus group with the research community there was encouraging support. The only suggested improvement was a personalisation aspect, which the IRS would have the potential to add, with a projected roll out in the next phase of IRS.
4. Is IRS available now? Yes, there is free access. However at this stage IRS is more of a tool than a service.
5. Comment from Fred Friend (JISC): I’m from the UK. If this is valuable, we’ll have to fight to protect these systems because of budget cuts and the publishers fighting. So, to keep it’s value, we’ll have to convince government about it.











 (
(
 (
(